Add Minerva core, to be integrated later
This commit is contained in:
parent
6459c71ac5
commit
1982668829
13
README.md
13
README.md
@ -6,13 +6,22 @@ A port of [riscv-formal](https://github.com/SymbioticEDA/riscv-formal) to nMigen
|
||||
|
||||
- [nMigen](https://github.com/m-labs/nmigen)
|
||||
|
||||
## Breakdown
|
||||
|
||||
_This section is currently a work in progress._
|
||||
|
||||
| Directory | Description |
|
||||
| --- | --- |
|
||||
| `insns` | Supported RISC-V instructions and ISAs |
|
||||
| `cores` | Example cores to be integrated with riscv-formal-nmigen (WIP) |
|
||||
|
||||
## Build
|
||||
|
||||
TODO
|
||||
This framework is not ready to be used to verify RISC-V compliant cores at the time of writing. Instructions for running the framework against such a core will be added once the framework is ready for use.
|
||||
|
||||
## Scope
|
||||
|
||||
As with the original riscv-formal, support is planned for the RV32I and RV64I base ISAs, as well as the M and C extensions and combinations thereof (e.g. RV32IM, RV64IMC).
|
||||
Support for the RV32I base ISA and RV32M extension are planned and well underway. Support for other ISAs in the original riscv-formal such as RV32C and their 64-bit counterparts may also be added in the future as time permits.
|
||||
|
||||
## License
|
||||
|
||||
|
||||
14
cores/minerva/.gitignore
vendored
Normal file
14
cores/minerva/.gitignore
vendored
Normal file
@ -0,0 +1,14 @@
|
||||
# Python
|
||||
__pycache__/
|
||||
/*.egg-info
|
||||
/.eggs
|
||||
|
||||
# tests
|
||||
**/test/spec_*/
|
||||
*.vcd
|
||||
*.gtkw
|
||||
|
||||
# misc user-created
|
||||
*.il
|
||||
*.v
|
||||
/build
|
||||
28
cores/minerva/LICENSE.txt
Normal file
28
cores/minerva/LICENSE.txt
Normal file
@ -0,0 +1,28 @@
|
||||
Copyright (C) 2018-2019 LambdaConcept
|
||||
|
||||
Redistribution and use in source and binary forms, with or without modification,
|
||||
are permitted provided that the following conditions are met:
|
||||
|
||||
1. Redistributions of source code must retain the above copyright notice, this
|
||||
list of conditions and the following disclaimer.
|
||||
2. Redistributions in binary form must reproduce the above copyright notice,
|
||||
this list of conditions and the following disclaimer in the documentation
|
||||
and/or other materials provided with the distribution.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
|
||||
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
|
||||
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
||||
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR
|
||||
ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
|
||||
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
|
||||
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
|
||||
ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
|
||||
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
|
||||
Other authors retain ownership of their contributions. If a submission can
|
||||
reasonably be considered independently copyrightable, it's yours and we
|
||||
encourage you to claim it with appropriate copyright notices. This submission
|
||||
then falls under the "otherwise noted" category. All submissions are strongly
|
||||
encouraged to use the two-clause BSD license reproduced above.
|
||||
91
cores/minerva/README.md
Normal file
91
cores/minerva/README.md
Normal file
@ -0,0 +1,91 @@
|
||||
# Minerva
|
||||
|
||||
## A 32-bit RISC-V soft processor
|
||||
|
||||
Minerva is a CPU core that currently implements the [RISC-V][1] RV32IM instruction set. Its microarchitecture is described in plain Python code using the [nMigen][2] toolbox.
|
||||
|
||||
### Quick start
|
||||
|
||||
Minerva currently requires Python 3.6+ and [nMigen][2] on its `master` branch.
|
||||
|
||||
python setup.py install
|
||||
python cli.py generate > minerva.v
|
||||
|
||||
To use Minerva in its minimal configuration, you need to wire the following ports to `minerva_cpu`:
|
||||
|
||||
* `clk`
|
||||
* `rst`
|
||||
* `ibus__*`
|
||||
* `dbus__*`
|
||||
* `external_interrupt`
|
||||
* `timer_interrupt`
|
||||
* `software_interrupt`
|
||||
|
||||
### Features
|
||||
|
||||
The microarchitecture of Minerva is largely inspired by the [LatticeMico32][3] processor.
|
||||
|
||||
Minerva is pipelined on 6 stages:
|
||||
|
||||
1. **Address**
|
||||
The address of the next instruction is calculated and sent to the instruction cache.
|
||||
2. **Fetch**
|
||||
The instruction is read from memory.
|
||||
3. **Decode**
|
||||
The instruction is decoded, and operands are either fetched from the register file or bypassed from the pipeline. Branches are predicted by the static branch predictor.
|
||||
4. **Execute**
|
||||
Simple instructions such as arithmetic and logical operations are completed at this stage.
|
||||
5. **Memory**
|
||||
More complicated instructions such as loads, stores and shifts require a second execution stage.
|
||||
6. **Writeback**
|
||||
Results produced by the instructions are written back to the register file.
|
||||
|
||||
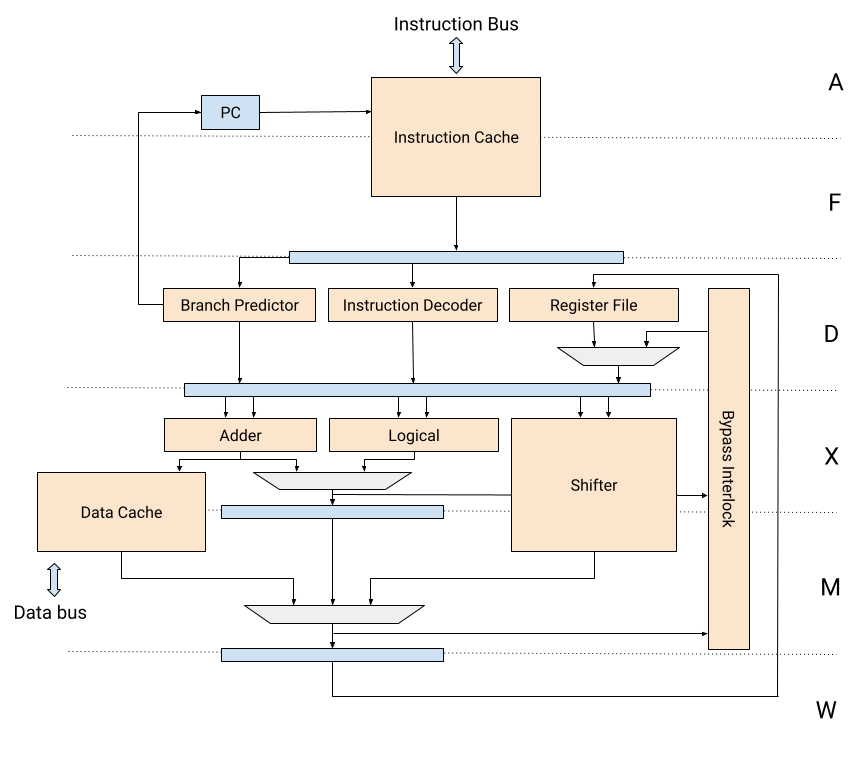
|
||||
|
||||
The L1 data cache is coupled to a write buffer. Store transactions are in this case done to the write buffer instead of the data bus. This enables stores to proceed in one clock cycle if the buffer isn't full, without having to wait for the bus transaction to complete. Store transactions are then completed in the background as the write buffer gets emptied to the data bus.
|
||||
|
||||
### Configuration
|
||||
|
||||
The following parameters can be used to configure the Minerva core.
|
||||
|
||||
| Parameter | Default value | Description |
|
||||
| ----------------- | -------------- | -------------------------------------------------- |
|
||||
| `reset_address` | `0x00000000` | Reset vector address |
|
||||
| `with_icache` | `False` | Enable the instruction cache |
|
||||
| `icache_nways` | `1` | Number of ways in the instruction cache |
|
||||
| `icache_nlines` | `128` | Number of lines in the instruction cache |
|
||||
| `icache_nwords` | `4` | Number of words in a line of the instruction cache |
|
||||
| `icache_base` | `0x00000000` | Base of the instruction cache address space |
|
||||
| `icache_limit` | `0x80000000` | Limit of the instruction cache address space |
|
||||
| `with_dcache` | `False` | Enable the data cache |
|
||||
| `dcache_nways` | `1` | Number of ways in the data cache |
|
||||
| `dcache_nlines` | `128` | Number of lines in the data cache |
|
||||
| `dcache_nwords` | `4` | Number of words in a line of the data cache |
|
||||
| `dcache_base` | `0x00000000` | Base of the data cache address space |
|
||||
| `dcache_limit` | `0x80000000` | Limit of the data cache address space |
|
||||
| `with_muldiv` | `False` | Enable RV32M support |
|
||||
| `with_debug` | `False` | Enable the Debug Module |
|
||||
| `with_trigger` | `False` | Enable the Trigger Module |
|
||||
| `nb_triggers` | `8` | Number of triggers |
|
||||
| `with_rvfi` | `False` | Enable the riscv-formal interface |
|
||||
|
||||
### Possible improvements
|
||||
|
||||
In no particular order:
|
||||
|
||||
* RV64I
|
||||
* Floating Point Unit
|
||||
* Stateful branch prediction
|
||||
* MMU
|
||||
* ...
|
||||
|
||||
If you are interested in sponsoring new features or improvements, get in touch at contact [at] lambdaconcept.com .
|
||||
|
||||
### License
|
||||
|
||||
Minerva is released under the permissive two-clause BSD license.
|
||||
See LICENSE file for full copyright and license information.
|
||||
|
||||
[1]: https://riscv.org/specifications/
|
||||
[2]: https://github.com/m-labs/nmigen/
|
||||
[3]: https://github.com/m-labs/lm32/
|
||||
114
cores/minerva/cli.py
Normal file
114
cores/minerva/cli.py
Normal file
@ -0,0 +1,114 @@
|
||||
import argparse
|
||||
import warnings
|
||||
from nmigen import cli
|
||||
|
||||
from minerva.core import Minerva
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
||||
|
||||
parser.add_argument("--reset-addr",
|
||||
type=lambda s: int(s, 16), default="0x00000000",
|
||||
help="reset vector address")
|
||||
|
||||
parser.add_argument("--with-icache",
|
||||
default=False, action="store_true",
|
||||
help="enable the instruction cache")
|
||||
parser.add_argument("--with-dcache",
|
||||
default=False, action="store_true",
|
||||
help="enable the data cache")
|
||||
parser.add_argument("--with-muldiv",
|
||||
default=False, action="store_true",
|
||||
help="enable RV32M support")
|
||||
parser.add_argument("--with-debug",
|
||||
default=False, action="store_true",
|
||||
help="enable the Debug Module")
|
||||
parser.add_argument("--with-trigger",
|
||||
default=False, action="store_true",
|
||||
help="enable the Trigger Module")
|
||||
parser.add_argument("--with-rvfi",
|
||||
default=False, action="store_true",
|
||||
help="enable the riscv-formal interface")
|
||||
|
||||
icache_group = parser.add_argument_group("icache options")
|
||||
icache_group.add_argument("--icache-nways",
|
||||
type=int, choices=[1, 2], default=1,
|
||||
help="number of ways")
|
||||
icache_group.add_argument("--icache-nlines",
|
||||
type=int, default=32,
|
||||
help="number of lines")
|
||||
icache_group.add_argument("--icache-nwords",
|
||||
type=int, choices=[4, 8, 16], default=4,
|
||||
help="number of words in a line")
|
||||
icache_group.add_argument("--icache-base",
|
||||
type=lambda s: int(s, 16), default="0x00000000",
|
||||
help="base address")
|
||||
icache_group.add_argument("--icache-limit",
|
||||
type=lambda s: int(s, 16), default="0x80000000",
|
||||
help="limit address")
|
||||
|
||||
dcache_group = parser.add_argument_group("dcache options")
|
||||
dcache_group.add_argument("--dcache-nways",
|
||||
type=int, choices=[1, 2], default=1,
|
||||
help="number of ways")
|
||||
dcache_group.add_argument("--dcache-nlines",
|
||||
type=int, default=32,
|
||||
help="number of lines")
|
||||
dcache_group.add_argument("--dcache-nwords",
|
||||
type=int, choices=[4, 8, 16], default=4,
|
||||
help="number of words in a line")
|
||||
dcache_group.add_argument("--dcache-base",
|
||||
type=lambda s: int(s, 16), default="0x00000000",
|
||||
help="base address")
|
||||
dcache_group.add_argument("--dcache-limit",
|
||||
type=lambda s: int(s, 16), default="0x80000000",
|
||||
help="limit address")
|
||||
|
||||
trigger_group = parser.add_argument_group("trigger options")
|
||||
trigger_group.add_argument("--nb-triggers",
|
||||
type=int, default=8,
|
||||
help="number of triggers")
|
||||
|
||||
cli.main_parser(parser)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.with_debug and not args.with_trigger:
|
||||
warnings.warn("Support for hardware breakpoints requires --with-trigger")
|
||||
|
||||
cpu = Minerva(args.reset_addr,
|
||||
args.with_icache, args.icache_nways, args.icache_nlines, args.icache_nwords,
|
||||
args.icache_base, args.icache_limit,
|
||||
args.with_dcache, args.dcache_nways, args.dcache_nlines, args.dcache_nwords,
|
||||
args.dcache_base, args.dcache_limit,
|
||||
args.with_muldiv,
|
||||
args.with_debug,
|
||||
args.with_trigger, args.nb_triggers,
|
||||
args.with_rvfi)
|
||||
|
||||
ports = [
|
||||
cpu.external_interrupt, cpu.timer_interrupt, cpu.software_interrupt,
|
||||
cpu.ibus.ack, cpu.ibus.adr, cpu.ibus.bte, cpu.ibus.cti, cpu.ibus.cyc, cpu.ibus.dat_r,
|
||||
cpu.ibus.dat_w, cpu.ibus.sel, cpu.ibus.stb, cpu.ibus.we, cpu.ibus.err,
|
||||
cpu.dbus.ack, cpu.dbus.adr, cpu.dbus.bte, cpu.dbus.cti, cpu.dbus.cyc, cpu.dbus.dat_r,
|
||||
cpu.dbus.dat_w, cpu.dbus.sel, cpu.dbus.stb, cpu.dbus.we, cpu.dbus.err
|
||||
]
|
||||
|
||||
if args.with_debug:
|
||||
ports += [cpu.jtag.tck, cpu.jtag.tdi, cpu.jtag.tdo, cpu.jtag.tms]
|
||||
|
||||
if args.with_rvfi:
|
||||
ports += [
|
||||
cpu.rvfi.valid, cpu.rvfi.order, cpu.rvfi.insn, cpu.rvfi.trap, cpu.rvfi.halt,
|
||||
cpu.rvfi.intr, cpu.rvfi.mode, cpu.rvfi.ixl, cpu.rvfi.rs1_addr, cpu.rvfi.rs2_addr,
|
||||
cpu.rvfi.rs1_rdata, cpu.rvfi.rs2_rdata, cpu.rvfi.rd_addr, cpu.rvfi.rd_wdata,
|
||||
cpu.rvfi.pc_rdata, cpu.rvfi.pc_wdata, cpu.rvfi.mem_addr, cpu.rvfi.mem_rmask,
|
||||
cpu.rvfi.mem_wmask, cpu.rvfi.mem_rdata, cpu.rvfi.mem_wdata
|
||||
]
|
||||
|
||||
cli.main_runner(parser, args, cpu, name="minerva_cpu", ports=ports)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
0
cores/minerva/minerva/__init__.py
Normal file
0
cores/minerva/minerva/__init__.py
Normal file
178
cores/minerva/minerva/cache.py
Normal file
178
cores/minerva/minerva/cache.py
Normal file
@ -0,0 +1,178 @@
|
||||
from nmigen import *
|
||||
from nmigen.asserts import *
|
||||
from nmigen.lib.coding import Encoder
|
||||
from nmigen.utils import log2_int
|
||||
|
||||
|
||||
__all__ = ["L1Cache"]
|
||||
|
||||
|
||||
class L1Cache(Elaboratable):
|
||||
def __init__(self, nways, nlines, nwords, base, limit):
|
||||
if not isinstance(nlines, int):
|
||||
raise TypeError("nlines must be an integer, not {!r}".format(nlines))
|
||||
if nlines == 0 or nlines & nlines - 1:
|
||||
raise ValueError("nlines must be a power of 2, not {}".format(nlines))
|
||||
if nwords not in {4, 8, 16}:
|
||||
raise ValueError("nwords must be 4, 8 or 16, not {!r}".format(nwords))
|
||||
if nways not in {1, 2}:
|
||||
raise ValueError("nways must be 1 or 2, not {!r}".format(nways))
|
||||
|
||||
if not isinstance(base, int):
|
||||
raise TypeError("base must be an integer, not {!r}".format(base))
|
||||
if base not in range(0, 2**32) or base & base - 1:
|
||||
raise ValueError("base must be 0 or a power of 2 (< 2**32), not {:#x}".format(base))
|
||||
if not isinstance(limit, int):
|
||||
raise TypeError("limit must be an integer, not {!r}".format(limit))
|
||||
if limit not in range(1, 2**32 + 1) or limit & limit - 1:
|
||||
raise ValueError("limit must be a power of 2 (<= 2**32), not {:#x}".format(limit))
|
||||
if base >= limit:
|
||||
raise ValueError("limit {:#x} must be greater than base {:#x}"
|
||||
.format(limit, base))
|
||||
|
||||
self.nways = nways
|
||||
self.nlines = nlines
|
||||
self.nwords = nwords
|
||||
self.base = base
|
||||
self.limit = limit
|
||||
|
||||
offsetbits = log2_int(nwords)
|
||||
linebits = log2_int(nlines)
|
||||
tagbits = log2_int(limit) - linebits - offsetbits - 2
|
||||
|
||||
self.s1_addr = Record([("offset", offsetbits), ("line", linebits), ("tag", tagbits)])
|
||||
self.s1_stall = Signal()
|
||||
self.s1_valid = Signal()
|
||||
self.s2_addr = Record.like(self.s1_addr)
|
||||
self.s2_re = Signal()
|
||||
self.s2_flush = Signal()
|
||||
self.s2_evict = Signal()
|
||||
self.s2_valid = Signal()
|
||||
self.bus_valid = Signal()
|
||||
self.bus_error = Signal()
|
||||
self.bus_rdata = Signal(32)
|
||||
|
||||
self.s2_miss = Signal()
|
||||
self.s2_flush_ack = Signal()
|
||||
self.s2_rdata = Signal(32)
|
||||
self.bus_re = Signal()
|
||||
self.bus_addr = Record.like(self.s1_addr)
|
||||
self.bus_last = Signal()
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
ways = Array(Record([("data", self.nwords * 32),
|
||||
("tag", self.s2_addr.tag.shape()),
|
||||
("valid", 1),
|
||||
("bus_re", 1)])
|
||||
for _ in range(self.nways))
|
||||
|
||||
if self.nways == 1:
|
||||
way_lru = Const(0)
|
||||
elif self.nways == 2:
|
||||
way_lru = Signal()
|
||||
with m.If(self.bus_re & self.bus_valid & self.bus_last & ~self.bus_error):
|
||||
m.d.sync += way_lru.eq(~way_lru)
|
||||
|
||||
m.d.comb += ways[way_lru].bus_re.eq(self.bus_re)
|
||||
|
||||
way_hit = m.submodules.way_hit = Encoder(self.nways)
|
||||
for j, way in enumerate(ways):
|
||||
m.d.comb += way_hit.i[j].eq((way.tag == self.s2_addr.tag) & way.valid)
|
||||
|
||||
m.d.comb += [
|
||||
self.s2_miss.eq(way_hit.n),
|
||||
self.s2_rdata.eq(ways[way_hit.o].data.word_select(self.s2_addr.offset, 32))
|
||||
]
|
||||
|
||||
flush_line = Signal(range(self.nlines), reset=self.nlines - 1)
|
||||
with m.If(self.s1_valid & ~self.s1_stall):
|
||||
m.d.sync += self.s2_flush_ack.eq(0)
|
||||
|
||||
with m.FSM() as fsm:
|
||||
last_offset = Signal.like(self.s2_addr.offset)
|
||||
|
||||
with m.State("CHECK"):
|
||||
with m.If(self.s2_valid):
|
||||
with m.If(self.s2_flush & ~self.s2_flush_ack):
|
||||
m.d.sync += flush_line.eq(flush_line.reset)
|
||||
m.next = "FLUSH"
|
||||
with m.Elif(self.s2_re & self.s2_miss):
|
||||
m.d.sync += [
|
||||
self.bus_addr.eq(self.s2_addr),
|
||||
self.bus_re.eq(1),
|
||||
last_offset.eq(self.s2_addr.offset - 1)
|
||||
]
|
||||
m.next = "REFILL"
|
||||
|
||||
with m.State("REFILL"):
|
||||
m.d.comb += self.bus_last.eq(self.bus_addr.offset == last_offset)
|
||||
with m.If(self.bus_valid):
|
||||
m.d.sync += self.bus_addr.offset.eq(self.bus_addr.offset + 1)
|
||||
with m.If(self.bus_valid & self.bus_last | self.bus_error):
|
||||
m.d.sync += self.bus_re.eq(0)
|
||||
with m.If(~self.bus_re & ~self.s1_stall):
|
||||
m.next = "CHECK"
|
||||
|
||||
with m.State("FLUSH"):
|
||||
with m.If(flush_line == 0):
|
||||
m.d.sync += self.s2_flush_ack.eq(1)
|
||||
m.next = "CHECK"
|
||||
with m.Else():
|
||||
m.d.sync += flush_line.eq(flush_line - 1)
|
||||
|
||||
if platform == "formal":
|
||||
with m.If(Initial()):
|
||||
m.d.comb += Assume(fsm.ongoing("CHECK"))
|
||||
|
||||
for way in ways:
|
||||
tag_mem = Memory(width=1 + len(way.tag), depth=self.nlines)
|
||||
tag_rp = tag_mem.read_port()
|
||||
tag_wp = tag_mem.write_port()
|
||||
m.submodules += tag_rp, tag_wp
|
||||
|
||||
data_mem = Memory(width=len(way.data), depth=self.nlines)
|
||||
data_rp = data_mem.read_port()
|
||||
data_wp = data_mem.write_port(granularity=32)
|
||||
m.submodules += data_rp, data_wp
|
||||
|
||||
mem_rp_addr = Signal.like(self.s1_addr.line)
|
||||
with m.If(self.s1_stall):
|
||||
m.d.comb += mem_rp_addr.eq(self.s2_addr.line)
|
||||
with m.Else():
|
||||
m.d.comb += mem_rp_addr.eq(self.s1_addr.line)
|
||||
|
||||
m.d.comb += [
|
||||
tag_rp.addr.eq(mem_rp_addr),
|
||||
data_rp.addr.eq(mem_rp_addr),
|
||||
Cat(way.tag, way.valid).eq(tag_rp.data),
|
||||
way.data.eq(data_rp.data),
|
||||
]
|
||||
|
||||
with m.If(fsm.ongoing("FLUSH")):
|
||||
m.d.comb += [
|
||||
tag_wp.addr.eq(flush_line),
|
||||
tag_wp.en.eq(1),
|
||||
tag_wp.data.eq(0),
|
||||
]
|
||||
with m.Elif(way.bus_re):
|
||||
m.d.comb += [
|
||||
tag_wp.addr.eq(self.bus_addr.line),
|
||||
tag_wp.en.eq(way.bus_re & self.bus_valid),
|
||||
tag_wp.data.eq(Cat(self.bus_addr.tag, self.bus_last & ~self.bus_error)),
|
||||
]
|
||||
with m.Else():
|
||||
m.d.comb += [
|
||||
tag_wp.addr.eq(self.s2_addr.line),
|
||||
tag_wp.en.eq(self.s2_evict & self.s2_valid & (way.tag == self.s2_addr.tag)),
|
||||
tag_wp.data.eq(0),
|
||||
]
|
||||
|
||||
m.d.comb += [
|
||||
data_wp.addr.eq(self.bus_addr.line),
|
||||
data_wp.en.bit_select(self.bus_addr.offset, 1).eq(way.bus_re & self.bus_valid),
|
||||
data_wp.data.eq(Repl(self.bus_rdata, self.nwords)),
|
||||
]
|
||||
|
||||
return m
|
||||
812
cores/minerva/minerva/core.py
Normal file
812
cores/minerva/minerva/core.py
Normal file
@ -0,0 +1,812 @@
|
||||
from functools import reduce
|
||||
from operator import or_
|
||||
from itertools import tee
|
||||
|
||||
from nmigen import *
|
||||
from nmigen.lib.coding import PriorityEncoder
|
||||
|
||||
from .isa import *
|
||||
from .stage import *
|
||||
from .csr import *
|
||||
|
||||
from .units.adder import *
|
||||
from .units.compare import *
|
||||
from .units.debug import *
|
||||
from .units.decoder import *
|
||||
from .units.divider import *
|
||||
from .units.exception import *
|
||||
from .units.fetch import *
|
||||
from .units.rvficon import *
|
||||
from .units.loadstore import *
|
||||
from .units.logic import *
|
||||
from .units.multiplier import *
|
||||
from .units.predict import *
|
||||
from .units.shifter import *
|
||||
from .units.trigger import *
|
||||
|
||||
from .units.debug.jtag import jtag_layout
|
||||
from .wishbone import wishbone_layout, WishboneArbiter
|
||||
|
||||
|
||||
__all__ = ["Minerva"]
|
||||
|
||||
|
||||
_af_layout = [
|
||||
("pc", (33, True)),
|
||||
]
|
||||
|
||||
|
||||
_fd_layout = [
|
||||
("pc", 32),
|
||||
("instruction", 32),
|
||||
("fetch_error", 1),
|
||||
("fetch_badaddr", 30)
|
||||
]
|
||||
|
||||
|
||||
_dx_layout = [
|
||||
("pc", 32),
|
||||
("instruction", 32),
|
||||
("fetch_error", 1),
|
||||
("fetch_badaddr", 30),
|
||||
("illegal", 1),
|
||||
("rd", 5),
|
||||
("rs1", 5),
|
||||
("rd_we", 1),
|
||||
("rs1_re", 1),
|
||||
("src1", 32),
|
||||
("src2", 32),
|
||||
("store_operand", 32),
|
||||
("bypass_x", 1),
|
||||
("bypass_m", 1),
|
||||
("funct3", 3),
|
||||
("load", 1),
|
||||
("store", 1),
|
||||
("adder_sub", 1),
|
||||
("logic", 1),
|
||||
("multiply", 1),
|
||||
("divide", 1),
|
||||
("shift", 1),
|
||||
("direction", 1),
|
||||
("sext", 1),
|
||||
("jump", 1),
|
||||
("compare", 1),
|
||||
("branch", 1),
|
||||
("branch_target", 32),
|
||||
("branch_predict_taken", 1),
|
||||
("fence_i", 1),
|
||||
("csr", 1),
|
||||
("csr_adr", 12),
|
||||
("csr_we", 1),
|
||||
("ecall", 1),
|
||||
("ebreak", 1),
|
||||
("mret", 1),
|
||||
]
|
||||
|
||||
|
||||
_xm_layout = [
|
||||
("pc", 32),
|
||||
("instruction", 32),
|
||||
("fetch_error", 1),
|
||||
("fetch_badaddr", 30),
|
||||
("illegal", 1),
|
||||
("loadstore_misaligned", 1),
|
||||
("ecall", 1),
|
||||
("ebreak", 1),
|
||||
("rd", 5),
|
||||
("rd_we", 1),
|
||||
("bypass_m", 1),
|
||||
("funct3", 3),
|
||||
("result", 32),
|
||||
("shift", 1),
|
||||
("load", 1),
|
||||
("store", 1),
|
||||
("store_data", 32),
|
||||
("compare", 1),
|
||||
("multiply", 1),
|
||||
("divide", 1),
|
||||
("condition_met", 1),
|
||||
("branch_target", 32),
|
||||
("branch_taken", 1),
|
||||
("branch_predict_taken", 1),
|
||||
("csr", 1),
|
||||
("csr_adr", 12),
|
||||
("csr_we", 1),
|
||||
("csr_result", 32),
|
||||
("mret", 1),
|
||||
("exception", 1)
|
||||
]
|
||||
|
||||
|
||||
_mw_layout = [
|
||||
("pc", 32),
|
||||
("rd", 5),
|
||||
("rd_we", 1),
|
||||
("funct3", 3),
|
||||
("result", 32),
|
||||
("load", 1),
|
||||
("load_data", 32),
|
||||
("multiply", 1),
|
||||
("exception", 1)
|
||||
]
|
||||
|
||||
|
||||
class Minerva(Elaboratable):
|
||||
def __init__(self, reset_address=0x00000000,
|
||||
with_icache=False,
|
||||
icache_nways=1, icache_nlines=32, icache_nwords=4, icache_base=0, icache_limit=2**31,
|
||||
with_dcache=False,
|
||||
dcache_nways=1, dcache_nlines=32, dcache_nwords=4, dcache_base=0, dcache_limit=2**31,
|
||||
with_muldiv=False,
|
||||
with_debug=False,
|
||||
with_trigger=False, nb_triggers=8,
|
||||
with_rvfi=False):
|
||||
self.external_interrupt = Signal(32)
|
||||
self.timer_interrupt = Signal()
|
||||
self.software_interrupt = Signal()
|
||||
self.ibus = Record(wishbone_layout)
|
||||
self.dbus = Record(wishbone_layout)
|
||||
|
||||
if with_debug:
|
||||
self.jtag = Record(jtag_layout)
|
||||
|
||||
if with_rvfi:
|
||||
self.rvfi = Record(rvfi_layout)
|
||||
|
||||
self.reset_address = reset_address
|
||||
self.with_icache = with_icache
|
||||
self.icache_args = icache_nways, icache_nlines, icache_nwords, icache_base, icache_limit
|
||||
self.with_dcache = with_dcache
|
||||
self.dcache_args = dcache_nways, dcache_nlines, dcache_nwords, dcache_base, dcache_limit
|
||||
self.with_muldiv = with_muldiv
|
||||
self.with_debug = with_debug
|
||||
self.with_trigger = with_trigger
|
||||
self.nb_triggers = nb_triggers
|
||||
self.with_rvfi = with_rvfi
|
||||
|
||||
def elaborate(self, platform):
|
||||
cpu = Module()
|
||||
|
||||
# pipeline stages
|
||||
|
||||
a = cpu.submodules.a = Stage(None, _af_layout)
|
||||
f = cpu.submodules.f = Stage(_af_layout, _fd_layout)
|
||||
d = cpu.submodules.d = Stage(_fd_layout, _dx_layout)
|
||||
x = cpu.submodules.x = Stage(_dx_layout, _xm_layout)
|
||||
m = cpu.submodules.m = Stage(_xm_layout, _mw_layout)
|
||||
w = cpu.submodules.w = Stage(_mw_layout, None)
|
||||
stages = a, f, d, x, m, w
|
||||
|
||||
sources, sinks = tee(stages)
|
||||
next(sinks)
|
||||
for s1, s2 in zip(sources, sinks):
|
||||
cpu.d.comb += s1.source.connect(s2.sink)
|
||||
|
||||
a.source.pc.reset = self.reset_address - 4
|
||||
cpu.d.comb += a.valid.eq(Const(1))
|
||||
|
||||
# units
|
||||
|
||||
pc_sel = cpu.submodules.pc_sel = PCSelector()
|
||||
data_sel = cpu.submodules.data_sel = DataSelector()
|
||||
adder = cpu.submodules.adder = Adder()
|
||||
compare = cpu.submodules.compare = CompareUnit()
|
||||
decoder = cpu.submodules.decoder = InstructionDecoder(self.with_muldiv)
|
||||
exception = cpu.submodules.exception = ExceptionUnit()
|
||||
logic = cpu.submodules.logic = LogicUnit()
|
||||
predict = cpu.submodules.predict = BranchPredictor()
|
||||
shifter = cpu.submodules.shifter = Shifter()
|
||||
|
||||
if self.with_icache:
|
||||
fetch = cpu.submodules.fetch = CachedFetchUnit(*self.icache_args)
|
||||
else:
|
||||
fetch = cpu.submodules.fetch = BareFetchUnit()
|
||||
|
||||
if self.with_dcache:
|
||||
loadstore = cpu.submodules.loadstore = CachedLoadStoreUnit(*self.dcache_args)
|
||||
else:
|
||||
loadstore = cpu.submodules.loadstore = BareLoadStoreUnit()
|
||||
|
||||
if self.with_muldiv:
|
||||
multiplier = Multiplier() if not self.with_rvfi else DummyMultiplier()
|
||||
divider = Divider() if not self.with_rvfi else DummyDivider()
|
||||
cpu.submodules.multiplier = multiplier
|
||||
cpu.submodules.divider = divider
|
||||
|
||||
if self.with_debug:
|
||||
debug = cpu.submodules.debug = DebugUnit()
|
||||
|
||||
if self.with_trigger:
|
||||
trigger = cpu.submodules.trigger = TriggerUnit(self.nb_triggers)
|
||||
|
||||
if self.with_rvfi:
|
||||
rvficon = cpu.submodules.rvficon = RVFIController()
|
||||
|
||||
# register files
|
||||
|
||||
gprf = Memory(width=32, depth=32)
|
||||
gprf_rp1 = gprf.read_port()
|
||||
gprf_rp2 = gprf.read_port()
|
||||
gprf_wp = gprf.write_port()
|
||||
cpu.submodules += gprf_rp1, gprf_rp2, gprf_wp
|
||||
|
||||
csrf = cpu.submodules.csrf = CSRFile()
|
||||
csrf_rp = csrf.read_port()
|
||||
csrf_wp = csrf.write_port()
|
||||
|
||||
csrf.add_csrs(exception.iter_csrs())
|
||||
if self.with_debug:
|
||||
csrf.add_csrs(debug.iter_csrs())
|
||||
if self.with_trigger:
|
||||
csrf.add_csrs(trigger.iter_csrs())
|
||||
|
||||
# pipeline logic
|
||||
|
||||
cpu.d.comb += [
|
||||
pc_sel.f_pc.eq(f.sink.pc),
|
||||
pc_sel.d_pc.eq(d.sink.pc),
|
||||
pc_sel.d_branch_predict_taken.eq(predict.d_branch_taken),
|
||||
pc_sel.d_branch_target.eq(predict.d_branch_target),
|
||||
pc_sel.d_valid.eq(d.valid),
|
||||
pc_sel.x_pc.eq(x.sink.pc),
|
||||
pc_sel.x_fence_i.eq(x.sink.fence_i),
|
||||
pc_sel.x_valid.eq(x.valid),
|
||||
pc_sel.m_branch_predict_taken.eq(m.sink.branch_predict_taken),
|
||||
pc_sel.m_branch_taken.eq(m.sink.branch_taken),
|
||||
pc_sel.m_branch_target.eq(m.sink.branch_target),
|
||||
pc_sel.m_exception.eq(exception.m_raise),
|
||||
pc_sel.m_mret.eq(m.sink.mret),
|
||||
pc_sel.m_valid.eq(m.valid),
|
||||
pc_sel.mtvec_r_base.eq(exception.mtvec.r.base),
|
||||
pc_sel.mepc_r_base.eq(exception.mepc.r.base)
|
||||
]
|
||||
|
||||
cpu.d.comb += [
|
||||
fetch.a_pc.eq(pc_sel.a_pc),
|
||||
fetch.a_stall.eq(a.stall),
|
||||
fetch.a_valid.eq(a.valid),
|
||||
fetch.f_stall.eq(f.stall),
|
||||
fetch.f_valid.eq(f.valid),
|
||||
fetch.ibus.connect(self.ibus)
|
||||
]
|
||||
|
||||
m.stall_on(fetch.a_busy & a.valid)
|
||||
m.stall_on(fetch.f_busy & f.valid)
|
||||
|
||||
if self.with_icache:
|
||||
flush_icache = x.sink.fence_i & x.valid
|
||||
if self.with_debug:
|
||||
flush_icache |= debug.resumereq
|
||||
|
||||
cpu.d.comb += [
|
||||
fetch.f_pc.eq(f.sink.pc),
|
||||
fetch.a_flush.eq(flush_icache)
|
||||
]
|
||||
|
||||
cpu.d.comb += [
|
||||
decoder.instruction.eq(d.sink.instruction)
|
||||
]
|
||||
|
||||
if self.with_debug:
|
||||
with cpu.If(debug.halt & debug.halted):
|
||||
cpu.d.comb += gprf_rp1.addr.eq(debug.gprf_addr)
|
||||
with cpu.Elif(~d.stall):
|
||||
cpu.d.comb += gprf_rp1.addr.eq(fetch.f_instruction[15:20])
|
||||
with cpu.Else():
|
||||
cpu.d.comb += gprf_rp1.addr.eq(decoder.rs1)
|
||||
|
||||
cpu.d.comb += debug.gprf_dat_r.eq(gprf_rp1.data)
|
||||
else:
|
||||
with cpu.If(~d.stall):
|
||||
cpu.d.comb += gprf_rp1.addr.eq(fetch.f_instruction[15:20])
|
||||
with cpu.Else():
|
||||
cpu.d.comb += gprf_rp1.addr.eq(decoder.rs1)
|
||||
|
||||
with cpu.If(~d.stall):
|
||||
cpu.d.comb += gprf_rp2.addr.eq(fetch.f_instruction[20:25])
|
||||
with cpu.Else():
|
||||
cpu.d.comb += gprf_rp2.addr.eq(decoder.rs2)
|
||||
|
||||
with cpu.If(~f.stall):
|
||||
cpu.d.sync += csrf_rp.addr.eq(fetch.f_instruction[20:32])
|
||||
cpu.d.comb += csrf_rp.en.eq(decoder.csr & d.valid)
|
||||
|
||||
# CSR set/clear instructions are translated to logic operations.
|
||||
x_csr_set_clear = x.sink.funct3[1]
|
||||
x_csr_clear = x_csr_set_clear & x.sink.funct3[0]
|
||||
x_csr_fmt_i = x.sink.funct3[2]
|
||||
x_csr_src1 = Mux(x_csr_fmt_i, x.sink.rs1, x.sink.src1)
|
||||
x_csr_src1 = Mux(x_csr_clear, ~x_csr_src1, x_csr_src1)
|
||||
x_csr_logic_op = x.sink.funct3 | 0b100
|
||||
|
||||
cpu.d.comb += [
|
||||
logic.op.eq(Mux(x.sink.csr, x_csr_logic_op, x.sink.funct3)),
|
||||
logic.src1.eq(Mux(x.sink.csr, x_csr_src1, x.sink.src1)),
|
||||
logic.src2.eq(x.sink.src2)
|
||||
]
|
||||
|
||||
cpu.d.comb += [
|
||||
adder.sub.eq(x.sink.adder_sub),
|
||||
adder.src1.eq(x.sink.src1),
|
||||
adder.src2.eq(x.sink.src2),
|
||||
]
|
||||
|
||||
if self.with_muldiv:
|
||||
cpu.d.comb += [
|
||||
multiplier.x_op.eq(x.sink.funct3),
|
||||
multiplier.x_src1.eq(x.sink.src1),
|
||||
multiplier.x_src2.eq(x.sink.src2),
|
||||
multiplier.x_stall.eq(x.stall),
|
||||
multiplier.m_stall.eq(m.stall)
|
||||
]
|
||||
|
||||
cpu.d.comb += [
|
||||
divider.x_op.eq(x.sink.funct3),
|
||||
divider.x_src1.eq(x.sink.src1),
|
||||
divider.x_src2.eq(x.sink.src2),
|
||||
divider.x_valid.eq(x.sink.valid),
|
||||
divider.x_stall.eq(x.stall)
|
||||
]
|
||||
|
||||
m.stall_on(divider.m_busy)
|
||||
|
||||
cpu.d.comb += [
|
||||
shifter.x_direction.eq(x.sink.direction),
|
||||
shifter.x_sext.eq(x.sink.sext),
|
||||
shifter.x_shamt.eq(x.sink.src2),
|
||||
shifter.x_src1.eq(x.sink.src1),
|
||||
shifter.x_stall.eq(x.stall)
|
||||
]
|
||||
|
||||
cpu.d.comb += [
|
||||
# compare.op is shared by compare and branch instructions.
|
||||
compare.op.eq(Mux(x.sink.compare, x.sink.funct3 << 1, x.sink.funct3)),
|
||||
compare.zero.eq(x.sink.src1 == x.sink.src2),
|
||||
compare.negative.eq(adder.result[-1]),
|
||||
compare.overflow.eq(adder.overflow),
|
||||
compare.carry.eq(adder.carry)
|
||||
]
|
||||
|
||||
cpu.d.comb += [
|
||||
exception.external_interrupt.eq(self.external_interrupt),
|
||||
exception.timer_interrupt.eq(self.timer_interrupt),
|
||||
exception.software_interrupt.eq(self.software_interrupt),
|
||||
exception.m_fetch_misaligned.eq(m.sink.branch_taken & m.sink.branch_target[:2].bool()),
|
||||
exception.m_fetch_error.eq(m.sink.fetch_error),
|
||||
exception.m_fetch_badaddr.eq(m.sink.fetch_badaddr),
|
||||
exception.m_load_misaligned.eq(m.sink.load & m.sink.loadstore_misaligned),
|
||||
exception.m_load_error.eq(loadstore.m_load_error),
|
||||
exception.m_store_misaligned.eq(m.sink.store & m.sink.loadstore_misaligned),
|
||||
exception.m_store_error.eq(loadstore.m_store_error),
|
||||
exception.m_loadstore_badaddr.eq(loadstore.m_badaddr),
|
||||
exception.m_branch_target.eq(m.sink.branch_target),
|
||||
exception.m_illegal.eq(m.sink.illegal),
|
||||
exception.m_ecall.eq(m.sink.ecall),
|
||||
exception.m_pc.eq(m.sink.pc),
|
||||
exception.m_instruction.eq(m.sink.instruction),
|
||||
exception.m_result.eq(m.sink.result),
|
||||
exception.m_mret.eq(m.sink.mret),
|
||||
exception.m_stall.eq(m.sink.stall),
|
||||
exception.m_valid.eq(m.valid)
|
||||
]
|
||||
|
||||
m_ebreak = m.sink.ebreak
|
||||
if self.with_debug:
|
||||
# If dcsr.ebreakm is set, EBREAK instructions enter Debug Mode.
|
||||
# We do not want to raise an exception in this case because Debug Mode
|
||||
# should be invisible to software execution.
|
||||
m_ebreak &= ~debug.dcsr_ebreakm
|
||||
if self.with_trigger:
|
||||
m_trigger_trap = Signal()
|
||||
with cpu.If(~x.stall):
|
||||
cpu.d.sync += m_trigger_trap.eq(trigger.x_trap)
|
||||
m_ebreak |= m_trigger_trap
|
||||
cpu.d.comb += exception.m_ebreak.eq(m_ebreak)
|
||||
|
||||
m.kill_on(m.source.exception & m.source.valid)
|
||||
|
||||
cpu.d.comb += [
|
||||
data_sel.x_offset.eq(adder.result[:2]),
|
||||
data_sel.x_funct3.eq(x.sink.funct3),
|
||||
data_sel.x_store_operand.eq(x.sink.store_operand),
|
||||
data_sel.w_offset.eq(w.sink.result[:2]),
|
||||
data_sel.w_funct3.eq(w.sink.funct3),
|
||||
data_sel.w_load_data.eq(w.sink.load_data)
|
||||
]
|
||||
|
||||
cpu.d.comb += [
|
||||
loadstore.x_addr.eq(adder.result),
|
||||
loadstore.x_mask.eq(data_sel.x_mask),
|
||||
loadstore.x_load.eq(x.sink.load),
|
||||
loadstore.x_store.eq(x.sink.store),
|
||||
loadstore.x_store_data.eq(data_sel.x_store_data),
|
||||
loadstore.x_stall.eq(x.stall),
|
||||
loadstore.x_valid.eq(x.valid),
|
||||
loadstore.m_stall.eq(m.stall),
|
||||
loadstore.m_valid.eq(m.valid)
|
||||
]
|
||||
|
||||
m.stall_on(loadstore.x_busy & x.valid)
|
||||
m.stall_on(loadstore.m_busy & m.valid)
|
||||
|
||||
if self.with_dcache:
|
||||
if self.with_debug:
|
||||
cpu.d.comb += loadstore.m_flush.eq(debug.resumereq)
|
||||
|
||||
cpu.d.comb += [
|
||||
loadstore.x_fence_i.eq(x.sink.fence_i),
|
||||
loadstore.m_load.eq(m.sink.load),
|
||||
loadstore.m_store.eq(m.sink.store),
|
||||
]
|
||||
|
||||
for s in a, f:
|
||||
s.kill_on(x.sink.fence_i & x.valid)
|
||||
|
||||
if self.with_debug:
|
||||
cpu.submodules.dbus_arbiter = dbus_arbiter = WishboneArbiter()
|
||||
debug_dbus_port = dbus_arbiter.port(priority=0)
|
||||
loadstore_dbus_port = dbus_arbiter.port(priority=1)
|
||||
cpu.d.comb += [
|
||||
loadstore.dbus.connect(loadstore_dbus_port),
|
||||
debug.dbus.connect(debug_dbus_port),
|
||||
dbus_arbiter.bus.connect(self.dbus),
|
||||
]
|
||||
else:
|
||||
cpu.d.comb += loadstore.dbus.connect(self.dbus)
|
||||
|
||||
# RAW hazard management
|
||||
|
||||
x_raw_rs1 = Signal()
|
||||
m_raw_rs1 = Signal()
|
||||
w_raw_rs1 = Signal()
|
||||
x_raw_rs2 = Signal()
|
||||
m_raw_rs2 = Signal()
|
||||
w_raw_rs2 = Signal()
|
||||
|
||||
x_raw_csr = Signal()
|
||||
m_raw_csr = Signal()
|
||||
|
||||
x_lock = Signal()
|
||||
m_lock = Signal()
|
||||
|
||||
cpu.d.comb += [
|
||||
x_raw_rs1.eq(x.sink.rd.any() & (x.sink.rd == decoder.rs1) & x.sink.rd_we),
|
||||
m_raw_rs1.eq(m.sink.rd.any() & (m.sink.rd == decoder.rs1) & m.sink.rd_we),
|
||||
w_raw_rs1.eq(w.sink.rd.any() & (w.sink.rd == decoder.rs1) & w.sink.rd_we),
|
||||
|
||||
x_raw_rs2.eq(x.sink.rd.any() & (x.sink.rd == decoder.rs2) & x.sink.rd_we),
|
||||
m_raw_rs2.eq(m.sink.rd.any() & (m.sink.rd == decoder.rs2) & m.sink.rd_we),
|
||||
w_raw_rs2.eq(w.sink.rd.any() & (w.sink.rd == decoder.rs2) & w.sink.rd_we),
|
||||
|
||||
x_raw_csr.eq((x.sink.csr_adr == decoder.immediate) & x.sink.csr_we),
|
||||
m_raw_csr.eq((m.sink.csr_adr == decoder.immediate) & m.sink.csr_we),
|
||||
|
||||
x_lock.eq(~x.sink.bypass_x & (decoder.rs1_re & x_raw_rs1 | decoder.rs2_re & x_raw_rs2)
|
||||
| decoder.csr & x_raw_csr),
|
||||
m_lock.eq(~m.sink.bypass_m & (decoder.rs1_re & m_raw_rs1 | decoder.rs2_re & m_raw_rs2)
|
||||
| decoder.csr & m_raw_csr),
|
||||
]
|
||||
|
||||
if self.with_debug:
|
||||
d.stall_on((x_lock & x.valid | m_lock & m.valid) & d.valid & ~debug.dcsr_step)
|
||||
else:
|
||||
d.stall_on((x_lock & x.valid | m_lock & m.valid) & d.valid)
|
||||
|
||||
# result selection
|
||||
|
||||
x_result = Signal(32)
|
||||
m_result = Signal(32)
|
||||
w_result = Signal(32)
|
||||
x_csr_result = Signal(32)
|
||||
|
||||
with cpu.If(x.sink.jump):
|
||||
cpu.d.comb += x_result.eq(x.sink.pc + 4)
|
||||
with cpu.Elif(x.sink.logic):
|
||||
cpu.d.comb += x_result.eq(logic.result)
|
||||
with cpu.Elif(x.sink.csr):
|
||||
cpu.d.comb += x_result.eq(x.sink.src2)
|
||||
with cpu.Else():
|
||||
cpu.d.comb += x_result.eq(adder.result)
|
||||
|
||||
with cpu.If(m.sink.compare):
|
||||
cpu.d.comb += m_result.eq(m.sink.condition_met)
|
||||
if self.with_muldiv:
|
||||
with cpu.Elif(m.sink.divide):
|
||||
cpu.d.comb += m_result.eq(divider.m_result)
|
||||
with cpu.Elif(m.sink.shift):
|
||||
cpu.d.comb += m_result.eq(shifter.m_result)
|
||||
with cpu.Else():
|
||||
cpu.d.comb += m_result.eq(m.sink.result)
|
||||
|
||||
with cpu.If(w.sink.load):
|
||||
cpu.d.comb += w_result.eq(data_sel.w_load_result)
|
||||
if self.with_muldiv:
|
||||
with cpu.Elif(w.sink.multiply):
|
||||
cpu.d.comb += w_result.eq(multiplier.w_result)
|
||||
with cpu.Else():
|
||||
cpu.d.comb += w_result.eq(w.sink.result)
|
||||
|
||||
with cpu.If(x_csr_set_clear):
|
||||
cpu.d.comb += x_csr_result.eq(logic.result)
|
||||
with cpu.Else():
|
||||
cpu.d.comb += x_csr_result.eq(x_csr_src1)
|
||||
|
||||
cpu.d.comb += [
|
||||
csrf_wp.en.eq(m.sink.csr & m.sink.csr_we & m.valid & ~exception.m_raise & ~m.stall),
|
||||
csrf_wp.addr.eq(m.sink.csr_adr),
|
||||
csrf_wp.data.eq(m.sink.csr_result)
|
||||
]
|
||||
|
||||
if self.with_debug:
|
||||
with cpu.If(debug.halt & debug.halted):
|
||||
cpu.d.comb += [
|
||||
gprf_wp.addr.eq(debug.gprf_addr),
|
||||
gprf_wp.en.eq(debug.gprf_we),
|
||||
gprf_wp.data.eq(debug.gprf_dat_w)
|
||||
]
|
||||
with cpu.Else():
|
||||
cpu.d.comb += [
|
||||
gprf_wp.en.eq((w.sink.rd != 0) & w.sink.rd_we & w.valid & ~w.sink.exception),
|
||||
gprf_wp.addr.eq(w.sink.rd),
|
||||
gprf_wp.data.eq(w_result)
|
||||
]
|
||||
else:
|
||||
cpu.d.comb += [
|
||||
gprf_wp.en.eq((w.sink.rd != 0) & w.sink.rd_we & w.valid),
|
||||
gprf_wp.addr.eq(w.sink.rd),
|
||||
gprf_wp.data.eq(w_result)
|
||||
]
|
||||
|
||||
# D stage operand selection
|
||||
|
||||
d_src1 = Signal(32)
|
||||
d_src2 = Signal(32)
|
||||
|
||||
with cpu.If(decoder.lui):
|
||||
cpu.d.comb += d_src1.eq(0)
|
||||
with cpu.Elif(decoder.auipc):
|
||||
cpu.d.comb += d_src1.eq(d.sink.pc)
|
||||
with cpu.Elif(decoder.rs1_re & (decoder.rs1 == 0)):
|
||||
cpu.d.comb += d_src1.eq(0)
|
||||
with cpu.Elif(x_raw_rs1 & x.sink.valid):
|
||||
cpu.d.comb += d_src1.eq(x_result)
|
||||
with cpu.Elif(m_raw_rs1 & m.sink.valid):
|
||||
cpu.d.comb += d_src1.eq(m_result)
|
||||
with cpu.Elif(w_raw_rs1 & w.sink.valid):
|
||||
cpu.d.comb += d_src1.eq(w_result)
|
||||
with cpu.Else():
|
||||
cpu.d.comb += d_src1.eq(gprf_rp1.data)
|
||||
|
||||
with cpu.If(decoder.csr):
|
||||
cpu.d.comb += d_src2.eq(csrf_rp.data)
|
||||
with cpu.Elif(~decoder.rs2_re):
|
||||
cpu.d.comb += d_src2.eq(decoder.immediate)
|
||||
with cpu.Elif(decoder.rs2 == 0):
|
||||
cpu.d.comb += d_src2.eq(0)
|
||||
with cpu.Elif(x_raw_rs2 & x.sink.valid):
|
||||
cpu.d.comb += d_src2.eq(x_result)
|
||||
with cpu.Elif(m_raw_rs2 & m.sink.valid):
|
||||
cpu.d.comb += d_src2.eq(m_result)
|
||||
with cpu.Elif(w_raw_rs2 & w.sink.valid):
|
||||
cpu.d.comb += d_src2.eq(w_result)
|
||||
with cpu.Else():
|
||||
cpu.d.comb += d_src2.eq(gprf_rp2.data)
|
||||
|
||||
# branch prediction
|
||||
|
||||
cpu.d.comb += [
|
||||
predict.d_branch.eq(decoder.branch),
|
||||
predict.d_jump.eq(decoder.jump),
|
||||
predict.d_offset.eq(decoder.immediate),
|
||||
predict.d_pc.eq(d.sink.pc),
|
||||
predict.d_rs1_re.eq(decoder.rs1_re)
|
||||
]
|
||||
|
||||
a.kill_on(predict.d_branch_taken & d.valid)
|
||||
for s in a, f:
|
||||
s.kill_on(m.sink.branch_predict_taken & ~m.sink.branch_taken & m.valid)
|
||||
for s in a, f, d:
|
||||
s.kill_on(~m.sink.branch_predict_taken & m.sink.branch_taken & m.valid)
|
||||
s.kill_on((exception.m_raise | m.sink.mret) & m.valid)
|
||||
|
||||
# debug unit
|
||||
|
||||
if self.with_debug:
|
||||
cpu.d.comb += [
|
||||
debug.jtag.connect(self.jtag),
|
||||
debug.x_pc.eq(x.sink.pc),
|
||||
debug.x_ebreak.eq(x.sink.ebreak),
|
||||
debug.x_stall.eq(x.stall),
|
||||
debug.m_branch_taken.eq(m.sink.branch_taken),
|
||||
debug.m_branch_target.eq(m.sink.branch_target),
|
||||
debug.m_mret.eq(m.sink.mret),
|
||||
debug.m_exception.eq(exception.m_raise),
|
||||
debug.m_pc.eq(m.sink.pc),
|
||||
debug.m_valid.eq(m.valid),
|
||||
debug.mepc_r_base.eq(exception.mepc.r.base),
|
||||
debug.mtvec_r_base.eq(exception.mtvec.r.base)
|
||||
]
|
||||
|
||||
if self.with_trigger:
|
||||
cpu.d.comb += debug.trigger_haltreq.eq(trigger.haltreq)
|
||||
else:
|
||||
cpu.d.comb += debug.trigger_haltreq.eq(Const(0))
|
||||
|
||||
csrf_debug_rp = csrf.read_port()
|
||||
csrf_debug_wp = csrf.write_port()
|
||||
cpu.d.comb += [
|
||||
csrf_debug_rp.addr.eq(debug.csrf_addr),
|
||||
csrf_debug_rp.en.eq(debug.csrf_re),
|
||||
debug.csrf_dat_r.eq(csrf_debug_rp.data),
|
||||
csrf_debug_wp.addr.eq(debug.csrf_addr),
|
||||
csrf_debug_wp.en.eq(debug.csrf_we),
|
||||
csrf_debug_wp.data.eq(debug.csrf_dat_w)
|
||||
]
|
||||
|
||||
x.stall_on(debug.halt)
|
||||
m.stall_on(debug.dcsr_step & m.valid & ~debug.halt)
|
||||
for s in a, f, d, x:
|
||||
s.kill_on(debug.killall)
|
||||
|
||||
halted = x.stall & ~reduce(or_, (s.valid for s in (m, w)))
|
||||
cpu.d.sync += debug.halted.eq(halted)
|
||||
|
||||
with cpu.If(debug.resumereq):
|
||||
with cpu.If(~debug.dbus_busy):
|
||||
cpu.d.comb += debug.resumeack.eq(1)
|
||||
cpu.d.sync += a.source.pc.eq(debug.dpc_value - 4)
|
||||
|
||||
if self.with_trigger:
|
||||
cpu.d.comb += [
|
||||
trigger.x_pc.eq(x.sink.pc),
|
||||
trigger.x_valid.eq(x.valid),
|
||||
]
|
||||
|
||||
if self.with_rvfi:
|
||||
cpu.d.comb += [
|
||||
rvficon.d_insn.eq(decoder.instruction),
|
||||
rvficon.d_rs1_addr.eq(Mux(decoder.rs1_re, decoder.rs1, 0)),
|
||||
rvficon.d_rs2_addr.eq(Mux(decoder.rs2_re, decoder.rs2, 0)),
|
||||
rvficon.d_rs1_rdata.eq(Mux(decoder.rs1_re, d_src1, 0)),
|
||||
rvficon.d_rs2_rdata.eq(Mux(decoder.rs2_re, d_src2, 0)),
|
||||
rvficon.d_stall.eq(d.stall),
|
||||
rvficon.x_mem_addr.eq(loadstore.x_addr[2:] << 2),
|
||||
rvficon.x_mem_wmask.eq(Mux(loadstore.x_store, loadstore.x_mask, 0)),
|
||||
rvficon.x_mem_rmask.eq(Mux(loadstore.x_load, loadstore.x_mask, 0)),
|
||||
rvficon.x_mem_wdata.eq(loadstore.x_store_data),
|
||||
rvficon.x_stall.eq(x.stall),
|
||||
rvficon.m_mem_rdata.eq(loadstore.m_load_data),
|
||||
rvficon.m_fetch_misaligned.eq(exception.m_fetch_misaligned),
|
||||
rvficon.m_illegal_insn.eq(m.sink.illegal),
|
||||
rvficon.m_load_misaligned.eq(exception.m_load_misaligned),
|
||||
rvficon.m_store_misaligned.eq(exception.m_store_misaligned),
|
||||
rvficon.m_exception.eq(exception.m_raise),
|
||||
rvficon.m_mret.eq(m.sink.mret),
|
||||
rvficon.m_branch_taken.eq(m.sink.branch_taken),
|
||||
rvficon.m_branch_target.eq(m.sink.branch_target),
|
||||
rvficon.m_pc_rdata.eq(m.sink.pc),
|
||||
rvficon.m_stall.eq(m.stall),
|
||||
rvficon.m_valid.eq(m.valid),
|
||||
rvficon.w_rd_addr.eq(Mux(gprf_wp.en, gprf_wp.addr, 0)),
|
||||
rvficon.w_rd_wdata.eq(Mux(gprf_wp.en, gprf_wp.data, 0)),
|
||||
rvficon.mtvec_r_base.eq(exception.mtvec.r.base),
|
||||
rvficon.mepc_r_value.eq(exception.mepc.r),
|
||||
rvficon.rvfi.connect(self.rvfi)
|
||||
]
|
||||
|
||||
# pipeline registers
|
||||
|
||||
# A/F
|
||||
with cpu.If(~a.stall):
|
||||
cpu.d.sync += a.source.pc.eq(fetch.a_pc)
|
||||
|
||||
# F/D
|
||||
with cpu.If(~f.stall):
|
||||
cpu.d.sync += [
|
||||
f.source.pc.eq(f.sink.pc),
|
||||
f.source.instruction.eq(fetch.f_instruction),
|
||||
f.source.fetch_error.eq(fetch.f_fetch_error),
|
||||
f.source.fetch_badaddr.eq(fetch.f_badaddr)
|
||||
]
|
||||
|
||||
# D/X
|
||||
with cpu.If(~d.stall):
|
||||
cpu.d.sync += [
|
||||
d.source.pc.eq(d.sink.pc),
|
||||
d.source.instruction.eq(d.sink.instruction),
|
||||
d.source.fetch_error.eq(d.sink.fetch_error),
|
||||
d.source.fetch_badaddr.eq(d.sink.fetch_badaddr),
|
||||
d.source.illegal.eq(decoder.illegal),
|
||||
d.source.rd.eq(decoder.rd),
|
||||
d.source.rs1.eq(decoder.rs1),
|
||||
d.source.rd_we.eq(decoder.rd_we),
|
||||
d.source.rs1_re.eq(decoder.rs1_re),
|
||||
d.source.bypass_x.eq(decoder.bypass_x),
|
||||
d.source.bypass_m.eq(decoder.bypass_m),
|
||||
d.source.funct3.eq(decoder.funct3),
|
||||
d.source.load.eq(decoder.load),
|
||||
d.source.store.eq(decoder.store),
|
||||
d.source.adder_sub.eq(decoder.adder & decoder.adder_sub
|
||||
| decoder.compare | decoder.branch),
|
||||
d.source.compare.eq(decoder.compare),
|
||||
d.source.logic.eq(decoder.logic),
|
||||
d.source.shift.eq(decoder.shift),
|
||||
d.source.direction.eq(decoder.direction),
|
||||
d.source.sext.eq(decoder.sext),
|
||||
d.source.jump.eq(decoder.jump),
|
||||
d.source.branch.eq(decoder.branch),
|
||||
d.source.fence_i.eq(decoder.fence_i),
|
||||
d.source.csr.eq(decoder.csr),
|
||||
d.source.csr_adr.eq(decoder.immediate),
|
||||
d.source.csr_we.eq(decoder.csr_we),
|
||||
d.source.ecall.eq(decoder.ecall),
|
||||
d.source.ebreak.eq(decoder.ebreak),
|
||||
d.source.mret.eq(decoder.mret),
|
||||
d.source.src1.eq(d_src1),
|
||||
d.source.src2.eq(Mux(decoder.store, decoder.immediate, d_src2)),
|
||||
d.source.store_operand.eq(d_src2),
|
||||
d.source.branch_predict_taken.eq(predict.d_branch_taken),
|
||||
d.source.branch_target.eq(predict.d_branch_target)
|
||||
]
|
||||
|
||||
if self.with_muldiv:
|
||||
cpu.d.sync += [
|
||||
d.source.multiply.eq(decoder.multiply),
|
||||
d.source.divide.eq(decoder.divide)
|
||||
]
|
||||
|
||||
# X/M
|
||||
with cpu.If(~x.stall):
|
||||
cpu.d.sync += [
|
||||
x.source.pc.eq(x.sink.pc),
|
||||
x.source.instruction.eq(x.sink.instruction),
|
||||
x.source.fetch_error.eq(x.sink.fetch_error),
|
||||
x.source.fetch_badaddr.eq(x.sink.fetch_badaddr),
|
||||
x.source.illegal.eq(x.sink.illegal),
|
||||
x.source.loadstore_misaligned.eq(data_sel.x_misaligned),
|
||||
x.source.ecall.eq(x.sink.ecall),
|
||||
x.source.ebreak.eq(x.sink.ebreak),
|
||||
x.source.rd.eq(x.sink.rd),
|
||||
x.source.rd_we.eq(x.sink.rd_we),
|
||||
x.source.bypass_m.eq(x.sink.bypass_m | x.sink.bypass_x),
|
||||
x.source.funct3.eq(x.sink.funct3),
|
||||
x.source.load.eq(x.sink.load),
|
||||
x.source.store.eq(x.sink.store),
|
||||
x.source.store_data.eq(loadstore.x_store_data),
|
||||
x.source.compare.eq(x.sink.compare),
|
||||
x.source.shift.eq(x.sink.shift),
|
||||
x.source.mret.eq(x.sink.mret),
|
||||
x.source.condition_met.eq(compare.condition_met),
|
||||
x.source.branch_taken.eq(x.sink.jump | x.sink.branch & compare.condition_met),
|
||||
x.source.branch_target.eq(Mux(x.sink.jump & x.sink.rs1_re, adder.result[1:] << 1, x.sink.branch_target)),
|
||||
x.source.branch_predict_taken.eq(x.sink.branch_predict_taken),
|
||||
x.source.csr.eq(x.sink.csr),
|
||||
x.source.csr_adr.eq(x.sink.csr_adr),
|
||||
x.source.csr_we.eq(x.sink.csr_we),
|
||||
x.source.csr_result.eq(x_csr_result),
|
||||
x.source.result.eq(x_result)
|
||||
]
|
||||
if self.with_muldiv:
|
||||
cpu.d.sync += [
|
||||
x.source.multiply.eq(x.sink.multiply),
|
||||
x.source.divide.eq(x.sink.divide)
|
||||
]
|
||||
|
||||
# M/W
|
||||
with cpu.If(~m.stall):
|
||||
cpu.d.sync += [
|
||||
m.source.pc.eq(m.sink.pc),
|
||||
m.source.rd.eq(m.sink.rd),
|
||||
m.source.load.eq(m.sink.load),
|
||||
m.source.funct3.eq(m.sink.funct3),
|
||||
m.source.load_data.eq(loadstore.m_load_data),
|
||||
m.source.rd_we.eq(m.sink.rd_we),
|
||||
m.source.result.eq(m_result),
|
||||
m.source.exception.eq(exception.m_raise)
|
||||
]
|
||||
if self.with_muldiv:
|
||||
cpu.d.sync += [
|
||||
m.source.multiply.eq(m.sink.multiply)
|
||||
]
|
||||
|
||||
return cpu
|
||||
98
cores/minerva/minerva/csr.py
Normal file
98
cores/minerva/minerva/csr.py
Normal file
@ -0,0 +1,98 @@
|
||||
from enum import Enum
|
||||
from collections import OrderedDict
|
||||
|
||||
from nmigen import *
|
||||
from nmigen.utils import bits_for
|
||||
|
||||
|
||||
__all__ = ["CSRAccess", "CSR", "AutoCSR", "CSRFile"]
|
||||
|
||||
|
||||
class CSRAccess(Enum):
|
||||
RW = 0
|
||||
RO = 1
|
||||
|
||||
|
||||
class CSR(Record):
|
||||
def __init__(self, addr, description, name=None, src_loc_at=0):
|
||||
fields = []
|
||||
mask = 0
|
||||
offset = 0
|
||||
for fname, shape, access in description:
|
||||
if isinstance(shape, int):
|
||||
shape = shape, False
|
||||
width, signed = shape
|
||||
fields.append((fname, shape))
|
||||
if access is CSRAccess.RW:
|
||||
mask |= ((1 << width) - 1) << offset
|
||||
offset += width
|
||||
|
||||
self.addr = addr
|
||||
self.mask = mask
|
||||
|
||||
super().__init__([
|
||||
("r", fields),
|
||||
("w", fields),
|
||||
("re", 1),
|
||||
("we", 1),
|
||||
], name=name, src_loc_at=1 + src_loc_at)
|
||||
|
||||
|
||||
class AutoCSR():
|
||||
def iter_csrs(self):
|
||||
for v in vars(self).values():
|
||||
if isinstance(v, CSR):
|
||||
yield v
|
||||
elif hasattr(v, "iter_csrs"):
|
||||
yield from v.iter_csrs()
|
||||
|
||||
|
||||
class CSRFile(Elaboratable):
|
||||
def __init__(self, width=32, depth=2**12):
|
||||
self.width = width
|
||||
self.depth = depth
|
||||
self._csr_map = OrderedDict()
|
||||
self._read_ports = []
|
||||
self._write_ports = []
|
||||
|
||||
def add_csrs(self, csrs):
|
||||
for csr in csrs:
|
||||
if not isinstance(csr, CSR):
|
||||
raise TypeError("Object {!r} is not a CSR".format(csr))
|
||||
if csr.addr in self._csr_map:
|
||||
raise ValueError("CSR address 0x{:x} has already been allocated"
|
||||
.format(csr.addr))
|
||||
self._csr_map[csr.addr] = csr
|
||||
|
||||
def read_port(self):
|
||||
port = Record([("addr", bits_for(self.depth)), ("en", 1), ("data", self.width)], name="rp")
|
||||
self._read_ports.append(port)
|
||||
return port
|
||||
|
||||
def write_port(self):
|
||||
port = Record([("addr", bits_for(self.depth)), ("en", 1), ("data", self.width)], name="wp")
|
||||
self._write_ports.append(port)
|
||||
return port
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
for rp in self._read_ports:
|
||||
with m.Switch(rp.addr):
|
||||
for addr, csr in self._csr_map.items():
|
||||
with m.Case(addr):
|
||||
m.d.comb += [
|
||||
csr.re.eq(rp.en),
|
||||
rp.data.eq(csr.r)
|
||||
]
|
||||
|
||||
for wp in self._write_ports:
|
||||
with m.Switch(wp.addr):
|
||||
for addr, csr in self._csr_map.items():
|
||||
with m.Case(addr):
|
||||
m.d.comb += csr.we.eq(wp.en)
|
||||
for i in range(self.width):
|
||||
rw = (1 << i) & csr.mask
|
||||
m.d.comb += csr.w[i].eq(wp.data[i] if rw else csr.r[i])
|
||||
|
||||
return m
|
||||
215
cores/minerva/minerva/isa.py
Normal file
215
cores/minerva/minerva/isa.py
Normal file
@ -0,0 +1,215 @@
|
||||
from .csr import *
|
||||
|
||||
|
||||
class Opcode:
|
||||
LUI = 0b01101
|
||||
AUIPC = 0b00101
|
||||
JAL = 0b11011
|
||||
JALR = 0b11001
|
||||
BRANCH = 0b11000
|
||||
LOAD = 0b00000
|
||||
STORE = 0b01000
|
||||
OP_IMM_32 = 0b00100
|
||||
OP_32 = 0b01100
|
||||
MISC_MEM = 0b00011
|
||||
SYSTEM = 0b11100
|
||||
|
||||
|
||||
class Funct3:
|
||||
BEQ = B = ADD = FENCE = PRIV = MUL = 0b000
|
||||
BNE = H = SLL = FENCEI = CSRRW = MULH = 0b001
|
||||
_ = W = SLT = _ = CSRRS = MULHSU = 0b010
|
||||
_ = _ = SLTU = _ = CSRRC = MULHU = 0b011
|
||||
BLT = BU = XOR = _ = _ = DIV = 0b100
|
||||
BGE = HU = SR = _ = CSRRWI = DIVU = 0b101
|
||||
BLTU = _ = OR = _ = CSRRSI = REM = 0b110
|
||||
BGEU = _ = AND = _ = CSRRCI = REMU = 0b111
|
||||
|
||||
|
||||
class Funct7:
|
||||
SRL = ADD = 0b0000000
|
||||
MULDIV = 0b0000001
|
||||
SRA = SUB = 0b0100000
|
||||
|
||||
|
||||
class Funct12:
|
||||
ECALL = 0b000000000000
|
||||
EBREAK = 0b000000000001
|
||||
MRET = 0b001100000010
|
||||
WFI = 0b000100000101
|
||||
|
||||
|
||||
class CSRIndex:
|
||||
MVENDORID = 0xF11
|
||||
MARCHID = 0xF12
|
||||
MIMPID = 0xF13
|
||||
MHARTID = 0xF14
|
||||
MSTATUS = 0x300
|
||||
MISA = 0x301
|
||||
MEDELEG = 0x302
|
||||
MIDELEG = 0x303
|
||||
MIE = 0x304
|
||||
MTVEC = 0x305
|
||||
MCOUTEREN = 0x306
|
||||
MSCRATCH = 0x340
|
||||
MEPC = 0x341
|
||||
MCAUSE = 0x342
|
||||
MTVAL = 0x343
|
||||
MIP = 0x344
|
||||
# µarch specific
|
||||
IRQ_MASK = 0x330
|
||||
IRQ_PENDING = 0x360
|
||||
# trigger module
|
||||
TSELECT = 0x7a0
|
||||
TDATA1 = 0x7a1
|
||||
TDATA2 = 0x7a2
|
||||
TDATA3 = 0x7a3
|
||||
TINFO = 0x7a4
|
||||
MCONTEXT = 0x7a8
|
||||
# debug module
|
||||
DCSR = 0x7b0
|
||||
DPC = 0x7b1
|
||||
|
||||
|
||||
class Cause:
|
||||
FETCH_MISALIGNED = 0
|
||||
FETCH_ACCESS_FAULT = 1
|
||||
ILLEGAL_INSTRUCTION = 2
|
||||
BREAKPOINT = 3
|
||||
LOAD_MISALIGNED = 4
|
||||
LOAD_ACCESS_FAULT = 5
|
||||
STORE_MISALIGNED = 6
|
||||
STORE_ACCESS_FAULT = 7
|
||||
ECALL_FROM_U = 8
|
||||
ECALL_FROM_S = 9
|
||||
ECALL_FROM_M = 11
|
||||
FETCH_PAGE_FAULT = 12
|
||||
LOAD_PAGE_FAULT = 13
|
||||
STORE_PAGE_FAULT = 15
|
||||
# interrupts
|
||||
U_SOFTWARE_INTERRUPT = 0
|
||||
S_SOFTWARE_INTERRUPT = 1
|
||||
M_SOFTWARE_INTERRUPT = 3
|
||||
U_TIMER_INTERRUPT = 4
|
||||
S_TIMER_INTERRUPT = 5
|
||||
M_TIMER_INTERRUPT = 7
|
||||
U_EXTERNAL_INTERRUPT = 8
|
||||
S_EXTERNAL_INTERRUPT = 9
|
||||
M_EXTERNAL_INTERRUPT = 11
|
||||
|
||||
|
||||
# CSR layouts
|
||||
|
||||
flat_layout = [
|
||||
("value", 32, CSRAccess.RW),
|
||||
]
|
||||
|
||||
|
||||
misa_layout = [
|
||||
("extensions", 26, CSRAccess.RW),
|
||||
("zero", 4, CSRAccess.RO),
|
||||
("mxl", 2, CSRAccess.RW),
|
||||
]
|
||||
|
||||
|
||||
mstatus_layout = [
|
||||
("uie", 1, CSRAccess.RO), # User Interrupt Enable
|
||||
("sie", 1, CSRAccess.RO), # Supervisor Interrupt Enable
|
||||
("zero0", 1, CSRAccess.RO),
|
||||
("mie", 1, CSRAccess.RW), # Machine Interrupt Enable
|
||||
("upie", 1, CSRAccess.RO), # User Previous Interrupt Enable
|
||||
("spie", 1, CSRAccess.RO), # Supervisor Previous Interrupt Enable
|
||||
("zero1", 1, CSRAccess.RO),
|
||||
("mpie", 1, CSRAccess.RW), # Machine Previous Interrupt Enable
|
||||
("spp", 1, CSRAccess.RO), # Supervisor Previous Privilege
|
||||
("zero2", 2, CSRAccess.RO),
|
||||
("mpp", 2, CSRAccess.RW), # Machine Previous Privilege
|
||||
("fs", 2, CSRAccess.RO), # FPU Status
|
||||
("xs", 2, CSRAccess.RO), # user-mode eXtensions Status
|
||||
("mprv", 1, CSRAccess.RO), # Modify PRiVilege
|
||||
("sum", 1, CSRAccess.RO), # Supervisor User Memory access
|
||||
("mxr", 1, CSRAccess.RO), # Make eXecutable Readable
|
||||
("tvm", 1, CSRAccess.RO), # Trap Virtual Memory
|
||||
("tw", 1, CSRAccess.RO), # Timeout Wait
|
||||
("tsr", 1, CSRAccess.RO), # Trap SRET
|
||||
("zero3", 8, CSRAccess.RO),
|
||||
("sd", 1, CSRAccess.RO), # State Dirty (set if XS or FS are set to dirty)
|
||||
]
|
||||
|
||||
|
||||
mtvec_layout = [
|
||||
("mode", 2, CSRAccess.RW),
|
||||
("base", 30, CSRAccess.RW),
|
||||
]
|
||||
|
||||
|
||||
mepc_layout = [
|
||||
("zero", 2, CSRAccess.RO), # 16-bit instructions are not supported
|
||||
("base", 30, CSRAccess.RW),
|
||||
]
|
||||
|
||||
|
||||
mip_layout = [
|
||||
("usip", 1, CSRAccess.RO),
|
||||
("ssip", 1, CSRAccess.RO),
|
||||
("zero0", 1, CSRAccess.RO),
|
||||
("msip", 1, CSRAccess.RW),
|
||||
("utip", 1, CSRAccess.RO),
|
||||
("stip", 1, CSRAccess.RO),
|
||||
("zero1", 1, CSRAccess.RO),
|
||||
("mtip", 1, CSRAccess.RW),
|
||||
("ueip", 1, CSRAccess.RO),
|
||||
("seip", 1, CSRAccess.RO),
|
||||
("zero2", 1, CSRAccess.RO),
|
||||
("meip", 1, CSRAccess.RW),
|
||||
("zero3", 20, CSRAccess.RO),
|
||||
]
|
||||
|
||||
|
||||
mie_layout = [
|
||||
("usie", 1, CSRAccess.RO),
|
||||
("ssie", 1, CSRAccess.RO),
|
||||
("zero0", 1, CSRAccess.RO),
|
||||
("msie", 1, CSRAccess.RW),
|
||||
("utie", 1, CSRAccess.RO),
|
||||
("stie", 1, CSRAccess.RO),
|
||||
("zero1", 1, CSRAccess.RO),
|
||||
("mtie", 1, CSRAccess.RW),
|
||||
("ueie", 1, CSRAccess.RO),
|
||||
("seie", 1, CSRAccess.RO),
|
||||
("zero2", 1, CSRAccess.RO),
|
||||
("meie", 1, CSRAccess.RW),
|
||||
("zero3", 20, CSRAccess.RO),
|
||||
]
|
||||
|
||||
|
||||
mcause_layout = [
|
||||
("ecode", 31, CSRAccess.RW),
|
||||
("interrupt", 1, CSRAccess.RW),
|
||||
]
|
||||
|
||||
|
||||
dcsr_layout = [
|
||||
("prv", 2, CSRAccess.RW), # Privilege level before Debug Mode was entered
|
||||
("step", 1, CSRAccess.RW), # Execute a single instruction and re-enter Debug Mode
|
||||
("nmip", 1, CSRAccess.RO), # A non-maskable interrupt is pending
|
||||
("mprven", 1, CSRAccess.RW), # Use mstatus.mprv in Debug Mode
|
||||
("zero0", 1, CSRAccess.RO),
|
||||
("cause", 3, CSRAccess.RO), # Explains why Debug Mode was entered
|
||||
("stoptime", 1, CSRAccess.RW), # Stop timer increment during Debug Mode
|
||||
("stopcount", 1, CSRAccess.RW), # Stop counter increment during Debug Mode
|
||||
("stepie", 1, CSRAccess.RW), # Enable interrupts during single stepping
|
||||
("ebreaku", 1, CSRAccess.RW), # EBREAKs in U-mode enter Debug Mode
|
||||
("ebreaks", 1, CSRAccess.RW), # EBREAKs in S-mode enter Debug Mode
|
||||
("zero1", 1, CSRAccess.RO),
|
||||
("ebreakm", 1, CSRAccess.RW), # EBREAKs in M-mode enter Debug Mode
|
||||
("zero2", 12, CSRAccess.RO),
|
||||
("xdebugver", 4, CSRAccess.RO), # External Debug specification version
|
||||
]
|
||||
|
||||
|
||||
tdata1_layout = [
|
||||
("data", 27, CSRAccess.RW),
|
||||
("dmode", 1, CSRAccess.RW),
|
||||
("type", 4, CSRAccess.RW),
|
||||
]
|
||||
100
cores/minerva/minerva/stage.py
Normal file
100
cores/minerva/minerva/stage.py
Normal file
@ -0,0 +1,100 @@
|
||||
from functools import reduce
|
||||
from operator import or_
|
||||
|
||||
from nmigen import *
|
||||
from nmigen.hdl.rec import *
|
||||
|
||||
|
||||
__all__ = ["Stage"]
|
||||
|
||||
|
||||
def _make_m2s(layout):
|
||||
r = []
|
||||
for f in layout:
|
||||
if isinstance(f[1], (int, tuple)):
|
||||
r.append((f[0], f[1], DIR_FANOUT))
|
||||
else:
|
||||
r.append((f[0], _make_m2s(f[1])))
|
||||
return r
|
||||
|
||||
|
||||
class _EndpointDescription:
|
||||
def __init__(self, payload_layout):
|
||||
self.payload_layout = payload_layout
|
||||
|
||||
def get_full_layout(self):
|
||||
reserved = {"valid", "stall", "kill"}
|
||||
attributed = set()
|
||||
for f in self.payload_layout:
|
||||
if f[0] in attributed:
|
||||
raise ValueError(f[0] + " already attributed in payload layout")
|
||||
if f[0] in reserved:
|
||||
raise ValueError(f[0] + " cannot be used in endpoint layout")
|
||||
attributed.add(f[0])
|
||||
|
||||
full_layout = [
|
||||
("valid", 1, DIR_FANOUT),
|
||||
("stall", 1, DIR_FANIN),
|
||||
("kill", 1, DIR_FANOUT),
|
||||
("payload", _make_m2s(self.payload_layout))
|
||||
]
|
||||
return full_layout
|
||||
|
||||
|
||||
class _Endpoint(Record):
|
||||
def __init__(self, layout):
|
||||
self.description = _EndpointDescription(layout)
|
||||
super().__init__(self.description.get_full_layout())
|
||||
|
||||
def __getattr__(self, name):
|
||||
try:
|
||||
return super().__getattr__(name)
|
||||
except AttributeError:
|
||||
return self.fields["payload"][name]
|
||||
|
||||
|
||||
class Stage(Elaboratable):
|
||||
def __init__(self, sink_layout, source_layout):
|
||||
self.kill = Signal()
|
||||
self.stall = Signal()
|
||||
self.valid = Signal()
|
||||
|
||||
if sink_layout is None and source_layout is None:
|
||||
raise ValueError
|
||||
if sink_layout is not None:
|
||||
self.sink = _Endpoint(sink_layout)
|
||||
if source_layout is not None:
|
||||
self.source = _Endpoint(source_layout)
|
||||
|
||||
self._kill_sources = []
|
||||
self._stall_sources = []
|
||||
|
||||
def kill_on(self, cond):
|
||||
self._kill_sources.append(cond)
|
||||
|
||||
def stall_on(self, cond):
|
||||
self._stall_sources.append(cond)
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
if hasattr(self, "sink"):
|
||||
m.d.comb += [
|
||||
self.valid.eq(self.sink.valid & ~self.sink.kill),
|
||||
self.sink.stall.eq(self.stall)
|
||||
]
|
||||
|
||||
if hasattr(self, "source"):
|
||||
with m.If(~self.stall):
|
||||
m.d.sync += self.source.valid.eq(self.valid)
|
||||
with m.Elif(~self.source.stall | self.kill):
|
||||
m.d.sync += self.source.valid.eq(0)
|
||||
self.stall_on(self.source.stall)
|
||||
m.d.comb += [
|
||||
self.source.kill.eq(self.kill),
|
||||
self.kill.eq(reduce(or_, self._kill_sources, 0))
|
||||
]
|
||||
|
||||
m.d.comb += self.stall.eq(reduce(or_, self._stall_sources, 0))
|
||||
|
||||
return m
|
||||
0
cores/minerva/minerva/test/__init__.py
Normal file
0
cores/minerva/minerva/test/__init__.py
Normal file
97
cores/minerva/minerva/test/test_cache.py
Normal file
97
cores/minerva/minerva/test/test_cache.py
Normal file
@ -0,0 +1,97 @@
|
||||
from nmigen import *
|
||||
from nmigen.test.utils import *
|
||||
from nmigen.asserts import *
|
||||
|
||||
from ..cache import L1Cache
|
||||
|
||||
|
||||
class L1CacheSpec(Elaboratable):
|
||||
def __init__(self, cache):
|
||||
self.cache = cache
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
m.submodules.dut = cache = self.cache
|
||||
|
||||
mem_addr = AnyConst(cache.bus_addr.shape())
|
||||
mem_data = AnyConst(cache.bus_rdata.shape())
|
||||
|
||||
with m.If(cache.bus_re & (cache.bus_addr == mem_addr)):
|
||||
m.d.comb += Assume(cache.bus_rdata == mem_data)
|
||||
|
||||
s1_re = AnySeq(1)
|
||||
s1_flush = AnySeq(1)
|
||||
s1_evict = AnySeq(1)
|
||||
s1_select = AnySeq(1)
|
||||
|
||||
with m.If(~cache.s1_stall):
|
||||
m.d.sync += [
|
||||
cache.s2_addr.eq(cache.s1_addr),
|
||||
cache.s2_re.eq(s1_re),
|
||||
cache.s2_flush.eq(s1_flush),
|
||||
cache.s2_evict.eq(s1_evict),
|
||||
cache.s2_valid.eq(cache.s1_valid)
|
||||
]
|
||||
|
||||
with m.If((cache.s2_flush & ~cache.s2_flush_ack | cache.s2_re & cache.s2_miss)
|
||||
& cache.s2_valid):
|
||||
m.d.comb += Assume(cache.s1_stall)
|
||||
|
||||
with m.If(Initial()):
|
||||
m.d.comb += Assume(~cache.s2_valid)
|
||||
m.d.comb += Assume(~cache.bus_re)
|
||||
|
||||
# Any hit at `mem_addr` must return `mem_data`.
|
||||
with m.If(cache.s2_re & (cache.s2_addr == mem_addr) & ~cache.s2_miss
|
||||
& cache.s2_valid):
|
||||
m.d.comb += Assert(cache.s2_rdata == mem_data)
|
||||
|
||||
# The next read at any address after a flush must miss.
|
||||
cache_empty = Signal()
|
||||
with m.If(cache.s2_flush & Rose(cache.s2_flush_ack) & cache.s2_valid):
|
||||
m.d.sync += cache_empty.eq(1)
|
||||
with m.If(cache.bus_re & cache.bus_valid & cache.bus_last & ~cache.bus_error):
|
||||
m.d.sync += cache_empty.eq(0)
|
||||
with m.If(cache.s2_re & cache.s2_valid & cache_empty):
|
||||
m.d.comb += Assert(cache.s2_miss)
|
||||
|
||||
# The next read at a refilled address must hit.
|
||||
line_valid = Signal()
|
||||
refill_addr = Record.like(cache.s2_addr)
|
||||
with m.If(cache.bus_re & cache.bus_valid & cache.bus_last & ~cache.bus_error):
|
||||
m.d.sync += line_valid.eq(1)
|
||||
m.d.sync += refill_addr.eq(cache.bus_addr)
|
||||
with m.If((cache.s2_flush | cache.s2_evict) & cache.s2_valid):
|
||||
m.d.sync += line_valid.eq(0)
|
||||
with m.If(cache.s2_re & cache.s2_valid & line_valid
|
||||
& (cache.s2_addr.line == refill_addr.line)
|
||||
& (cache.s2_addr.tag == refill_addr.tag)):
|
||||
m.d.comb += Assert(~cache.s2_miss)
|
||||
|
||||
# The next read at an evicted address must miss.
|
||||
line_empty = Signal()
|
||||
evict_addr = Record.like(cache.s2_addr)
|
||||
with m.If(cache.s2_evict & cache.s2_valid):
|
||||
m.d.sync += line_empty.eq(1)
|
||||
m.d.sync += evict_addr.eq(cache.s2_addr)
|
||||
with m.If(cache.bus_re & cache.bus_valid & cache.bus_last
|
||||
& (cache.bus_addr.line == evict_addr.line)):
|
||||
m.d.sync += line_empty.eq(0)
|
||||
with m.If(cache.s2_re & cache.s2_valid & line_empty
|
||||
& (cache.s2_addr.line == evict_addr.line)
|
||||
& (cache.s2_addr.tag == evict_addr.tag)):
|
||||
m.d.comb += Assert(cache.s2_miss)
|
||||
|
||||
return m
|
||||
|
||||
|
||||
# FIXME: FHDLTestCase is internal to nMigen, we shouldn't use it.
|
||||
class L1CacheTestCase(FHDLTestCase):
|
||||
def check(self, cache):
|
||||
self.assertFormal(L1CacheSpec(cache), mode="bmc", depth=12)
|
||||
|
||||
def test_direct_mapped(self):
|
||||
self.check(L1Cache(nways=1, nlines=2, nwords=4, base=0, limit=64))
|
||||
|
||||
def test_2_ways(self):
|
||||
self.check(L1Cache(nways=2, nlines=2, nwords=4, base=0, limit=64))
|
||||
164
cores/minerva/minerva/test/test_units_divider.py
Normal file
164
cores/minerva/minerva/test/test_units_divider.py
Normal file
@ -0,0 +1,164 @@
|
||||
import unittest
|
||||
|
||||
from nmigen import *
|
||||
from nmigen.back.pysim import *
|
||||
|
||||
from ..units.divider import *
|
||||
from ..isa import Funct3
|
||||
|
||||
|
||||
def test_op(funct3, src1, src2, result):
|
||||
def test(self):
|
||||
with Simulator(self.dut) as sim:
|
||||
def process():
|
||||
yield self.dut.x_op.eq(funct3)
|
||||
yield self.dut.x_src1.eq(src1)
|
||||
yield self.dut.x_src2.eq(src2)
|
||||
yield self.dut.x_valid.eq(1)
|
||||
yield self.dut.x_stall.eq(0)
|
||||
yield Tick()
|
||||
yield self.dut.x_valid.eq(0)
|
||||
yield Tick()
|
||||
while (yield self.dut.m_busy):
|
||||
yield Tick()
|
||||
self.assertEqual((yield self.dut.m_result), result)
|
||||
sim.add_clock(1e-6)
|
||||
sim.add_sync_process(process)
|
||||
sim.run()
|
||||
return test
|
||||
|
||||
|
||||
class DividerTestCase(unittest.TestCase):
|
||||
def setUp(self):
|
||||
self.dut = Divider()
|
||||
|
||||
# Test cases are taken from the riscv-compliance testbench:
|
||||
# https://github.com/riscv/riscv-compliance/tree/master/riscv-test-suite/rv32im
|
||||
|
||||
# DIV ------------------------------------------------------------------------
|
||||
|
||||
test_div_0 = test_op(Funct3.DIV, 0x00000000, 0x00000000, result=0xffffffff)
|
||||
test_div_1 = test_op(Funct3.DIV, 0x00000000, 0x00000001, result=0x00000000)
|
||||
test_div_2 = test_op(Funct3.DIV, 0x00000000, 0xffffffff, result=0x00000000)
|
||||
test_div_3 = test_op(Funct3.DIV, 0x00000000, 0x7fffffff, result=0x00000000)
|
||||
test_div_4 = test_op(Funct3.DIV, 0x00000000, 0x80000000, result=0x00000000)
|
||||
|
||||
test_div_5 = test_op(Funct3.DIV, 0x00000001, 0x00000000, result=0xffffffff)
|
||||
test_div_6 = test_op(Funct3.DIV, 0x00000001, 0x00000001, result=0x00000001)
|
||||
test_div_7 = test_op(Funct3.DIV, 0x00000001, 0xffffffff, result=0xffffffff)
|
||||
test_div_8 = test_op(Funct3.DIV, 0x00000001, 0x7fffffff, result=0x00000000)
|
||||
test_div_9 = test_op(Funct3.DIV, 0x00000001, 0x80000000, result=0x00000000)
|
||||
|
||||
test_div_10 = test_op(Funct3.DIV, 0xffffffff, 0x00000000, result=0xffffffff)
|
||||
test_div_11 = test_op(Funct3.DIV, 0xffffffff, 0x00000001, result=0xffffffff)
|
||||
test_div_12 = test_op(Funct3.DIV, 0xffffffff, 0xffffffff, result=0x00000001)
|
||||
test_div_13 = test_op(Funct3.DIV, 0xffffffff, 0x7fffffff, result=0x00000000)
|
||||
test_div_14 = test_op(Funct3.DIV, 0xffffffff, 0x80000000, result=0x00000000)
|
||||
|
||||
test_div_15 = test_op(Funct3.DIV, 0x7fffffff, 0x00000000, result=0xffffffff)
|
||||
test_div_16 = test_op(Funct3.DIV, 0x7fffffff, 0x00000001, result=0x7fffffff)
|
||||
test_div_17 = test_op(Funct3.DIV, 0x7fffffff, 0xffffffff, result=0x80000001)
|
||||
test_div_18 = test_op(Funct3.DIV, 0x7fffffff, 0x7fffffff, result=0x00000001)
|
||||
test_div_19 = test_op(Funct3.DIV, 0x7fffffff, 0x80000000, result=0x00000000)
|
||||
|
||||
test_div_20 = test_op(Funct3.DIV, 0x80000000, 0x00000000, result=0xffffffff)
|
||||
test_div_21 = test_op(Funct3.DIV, 0x80000000, 0x00000001, result=0x80000000)
|
||||
test_div_22 = test_op(Funct3.DIV, 0x80000000, 0xffffffff, result=0x80000000)
|
||||
test_div_23 = test_op(Funct3.DIV, 0x80000000, 0x7fffffff, result=0xffffffff)
|
||||
test_div_24 = test_op(Funct3.DIV, 0x80000000, 0x80000000, result=0x00000001)
|
||||
|
||||
# DIVU -----------------------------------------------------------------------
|
||||
|
||||
test_divu_0 = test_op(Funct3.DIVU, 0x00000000, 0x00000000, result=0xffffffff)
|
||||
test_divu_1 = test_op(Funct3.DIVU, 0x00000000, 0x00000001, result=0x00000000)
|
||||
test_divu_2 = test_op(Funct3.DIVU, 0x00000000, 0xffffffff, result=0x00000000)
|
||||
test_divu_3 = test_op(Funct3.DIVU, 0x00000000, 0x7fffffff, result=0x00000000)
|
||||
test_divu_4 = test_op(Funct3.DIVU, 0x00000000, 0x80000000, result=0x00000000)
|
||||
|
||||
test_divu_5 = test_op(Funct3.DIVU, 0x00000001, 0x00000000, result=0xffffffff)
|
||||
test_divu_6 = test_op(Funct3.DIVU, 0x00000001, 0x00000001, result=0x00000001)
|
||||
test_divu_7 = test_op(Funct3.DIVU, 0x00000001, 0xffffffff, result=0x00000000)
|
||||
test_divu_8 = test_op(Funct3.DIVU, 0x00000001, 0x7fffffff, result=0x00000000)
|
||||
test_divu_9 = test_op(Funct3.DIVU, 0x00000001, 0x80000000, result=0x00000000)
|
||||
|
||||
test_divu_10 = test_op(Funct3.DIVU, 0xffffffff, 0x00000000, result=0xffffffff)
|
||||
test_divu_11 = test_op(Funct3.DIVU, 0xffffffff, 0x00000001, result=0xffffffff)
|
||||
test_divu_12 = test_op(Funct3.DIVU, 0xffffffff, 0xffffffff, result=0x00000001)
|
||||
test_divu_13 = test_op(Funct3.DIVU, 0xffffffff, 0x7fffffff, result=0x00000002)
|
||||
test_divu_14 = test_op(Funct3.DIVU, 0xffffffff, 0x80000000, result=0x00000001)
|
||||
|
||||
test_divu_15 = test_op(Funct3.DIVU, 0x7fffffff, 0x00000000, result=0xffffffff)
|
||||
test_divu_16 = test_op(Funct3.DIVU, 0x7fffffff, 0x00000001, result=0x7fffffff)
|
||||
test_divu_17 = test_op(Funct3.DIVU, 0x7fffffff, 0xffffffff, result=0x00000000)
|
||||
test_divu_18 = test_op(Funct3.DIVU, 0x7fffffff, 0x7fffffff, result=0x00000001)
|
||||
test_divu_19 = test_op(Funct3.DIVU, 0x7fffffff, 0x80000000, result=0x00000000)
|
||||
|
||||
test_divu_20 = test_op(Funct3.DIVU, 0x80000000, 0x00000000, result=0xffffffff)
|
||||
test_divu_21 = test_op(Funct3.DIVU, 0x80000000, 0x00000001, result=0x80000000)
|
||||
test_divu_22 = test_op(Funct3.DIVU, 0x80000000, 0xffffffff, result=0x00000000)
|
||||
test_divu_23 = test_op(Funct3.DIVU, 0x80000000, 0x7fffffff, result=0x00000001)
|
||||
test_divu_24 = test_op(Funct3.DIVU, 0x80000000, 0x80000000, result=0x00000001)
|
||||
|
||||
# REM ------------------------------------------------------------------------
|
||||
|
||||
test_rem_0 = test_op(Funct3.REM, 0x00000000, 0x00000000, result=0x00000000)
|
||||
test_rem_1 = test_op(Funct3.REM, 0x00000000, 0x00000001, result=0x00000000)
|
||||
test_rem_2 = test_op(Funct3.REM, 0x00000000, 0xffffffff, result=0x00000000)
|
||||
test_rem_3 = test_op(Funct3.REM, 0x00000000, 0x7fffffff, result=0x00000000)
|
||||
test_rem_4 = test_op(Funct3.REM, 0x00000000, 0x80000000, result=0x00000000)
|
||||
|
||||
test_rem_5 = test_op(Funct3.REM, 0x00000001, 0x00000000, result=0x00000001)
|
||||
test_rem_6 = test_op(Funct3.REM, 0x00000001, 0x00000001, result=0x00000000)
|
||||
test_rem_7 = test_op(Funct3.REM, 0x00000001, 0xffffffff, result=0x00000000)
|
||||
test_rem_8 = test_op(Funct3.REM, 0x00000001, 0x7fffffff, result=0x00000001)
|
||||
test_rem_9 = test_op(Funct3.REM, 0x00000001, 0x80000000, result=0x00000001)
|
||||
|
||||
test_rem_10 = test_op(Funct3.REM, 0xffffffff, 0x00000000, result=0xffffffff)
|
||||
test_rem_11 = test_op(Funct3.REM, 0xffffffff, 0x00000001, result=0x00000000)
|
||||
test_rem_12 = test_op(Funct3.REM, 0xffffffff, 0xffffffff, result=0x00000000)
|
||||
test_rem_13 = test_op(Funct3.REM, 0xffffffff, 0x7fffffff, result=0xffffffff)
|
||||
test_rem_14 = test_op(Funct3.REM, 0xffffffff, 0x80000000, result=0xffffffff)
|
||||
|
||||
test_rem_15 = test_op(Funct3.REM, 0x7fffffff, 0x00000000, result=0x7fffffff)
|
||||
test_rem_16 = test_op(Funct3.REM, 0x7fffffff, 0x00000001, result=0x00000000)
|
||||
test_rem_17 = test_op(Funct3.REM, 0x7fffffff, 0xffffffff, result=0x00000000)
|
||||
test_rem_18 = test_op(Funct3.REM, 0x7fffffff, 0x7fffffff, result=0x00000000)
|
||||
test_rem_19 = test_op(Funct3.REM, 0x7fffffff, 0x80000000, result=0x7fffffff)
|
||||
|
||||
test_rem_20 = test_op(Funct3.REM, 0x80000000, 0x00000000, result=0x80000000)
|
||||
test_rem_21 = test_op(Funct3.REM, 0x80000000, 0x00000001, result=0x00000000)
|
||||
test_rem_22 = test_op(Funct3.REM, 0x80000000, 0xffffffff, result=0x00000000)
|
||||
test_rem_23 = test_op(Funct3.REM, 0x80000000, 0x7fffffff, result=0xffffffff)
|
||||
test_rem_24 = test_op(Funct3.REM, 0x80000000, 0x80000000, result=0x00000000)
|
||||
|
||||
# REMU -----------------------------------------------------------------------
|
||||
|
||||
test_remu_0 = test_op(Funct3.REMU, 0x00000000, 0x00000000, result=0x00000000)
|
||||
test_remu_1 = test_op(Funct3.REMU, 0x00000000, 0x00000001, result=0x00000000)
|
||||
test_remu_2 = test_op(Funct3.REMU, 0x00000000, 0xffffffff, result=0x00000000)
|
||||
test_remu_3 = test_op(Funct3.REMU, 0x00000000, 0x7fffffff, result=0x00000000)
|
||||
test_remu_4 = test_op(Funct3.REMU, 0x00000000, 0x80000000, result=0x00000000)
|
||||
|
||||
test_remu_5 = test_op(Funct3.REMU, 0x00000001, 0x00000000, result=0x00000001)
|
||||
test_remu_6 = test_op(Funct3.REMU, 0x00000001, 0x00000001, result=0x00000000)
|
||||
test_remu_7 = test_op(Funct3.REMU, 0x00000001, 0xffffffff, result=0x00000001)
|
||||
test_remu_8 = test_op(Funct3.REMU, 0x00000001, 0x7fffffff, result=0x00000001)
|
||||
test_remu_9 = test_op(Funct3.REMU, 0x00000001, 0x80000000, result=0x00000001)
|
||||
|
||||
test_remu_10 = test_op(Funct3.REMU, 0xffffffff, 0x00000000, result=0xffffffff)
|
||||
test_remu_11 = test_op(Funct3.REMU, 0xffffffff, 0x00000001, result=0x00000000)
|
||||
test_remu_12 = test_op(Funct3.REMU, 0xffffffff, 0xffffffff, result=0x00000000)
|
||||
test_remu_13 = test_op(Funct3.REMU, 0xffffffff, 0x7fffffff, result=0x00000001)
|
||||
test_remu_14 = test_op(Funct3.REMU, 0xffffffff, 0x80000000, result=0x7fffffff)
|
||||
|
||||
test_remu_15 = test_op(Funct3.REMU, 0x7fffffff, 0x00000000, result=0x7fffffff)
|
||||
test_remu_16 = test_op(Funct3.REMU, 0x7fffffff, 0x00000001, result=0x00000000)
|
||||
test_remu_17 = test_op(Funct3.REMU, 0x7fffffff, 0xffffffff, result=0x7fffffff)
|
||||
test_remu_18 = test_op(Funct3.REMU, 0x7fffffff, 0x7fffffff, result=0x00000000)
|
||||
test_remu_19 = test_op(Funct3.REMU, 0x7fffffff, 0x80000000, result=0x7fffffff)
|
||||
|
||||
test_remu_20 = test_op(Funct3.REMU, 0x80000000, 0x00000000, result=0x80000000)
|
||||
test_remu_21 = test_op(Funct3.REMU, 0x80000000, 0x00000001, result=0x00000000)
|
||||
test_remu_22 = test_op(Funct3.REMU, 0x80000000, 0xffffffff, result=0x80000000)
|
||||
test_remu_23 = test_op(Funct3.REMU, 0x80000000, 0x7fffffff, result=0x00000001)
|
||||
test_remu_24 = test_op(Funct3.REMU, 0x80000000, 0x80000000, result=0x00000000)
|
||||
162
cores/minerva/minerva/test/test_units_multiplier.py
Normal file
162
cores/minerva/minerva/test/test_units_multiplier.py
Normal file
@ -0,0 +1,162 @@
|
||||
import unittest
|
||||
|
||||
from nmigen import *
|
||||
from nmigen.back.pysim import *
|
||||
|
||||
from ..units.multiplier import *
|
||||
from ..isa import Funct3
|
||||
|
||||
|
||||
def test_op(funct3, src1, src2, result):
|
||||
def test(self):
|
||||
with Simulator(self.dut) as sim:
|
||||
def process():
|
||||
yield self.dut.x_op.eq(funct3)
|
||||
yield self.dut.x_src1.eq(src1)
|
||||
yield self.dut.x_src2.eq(src2)
|
||||
yield self.dut.x_stall.eq(0)
|
||||
yield Tick()
|
||||
yield self.dut.m_stall.eq(0)
|
||||
yield Tick()
|
||||
yield Tick()
|
||||
self.assertEqual((yield self.dut.w_result), result)
|
||||
sim.add_clock(1e-6)
|
||||
sim.add_sync_process(process)
|
||||
sim.run()
|
||||
return test
|
||||
|
||||
|
||||
class MultiplierTestCase(unittest.TestCase):
|
||||
def setUp(self):
|
||||
self.dut = Multiplier()
|
||||
|
||||
# Test cases are taken from the riscv-compliance testbench:
|
||||
# https://github.com/riscv/riscv-compliance/tree/master/riscv-test-suite/rv32im
|
||||
|
||||
# MUL ----------------------------------------------------------------------------
|
||||
|
||||
test_mul_0 = test_op(Funct3.MUL, 0x00000000, 0x00000000, result=0x00000000)
|
||||
test_mul_1 = test_op(Funct3.MUL, 0x00000000, 0x00000001, result=0x00000000)
|
||||
test_mul_2 = test_op(Funct3.MUL, 0x00000000, 0xffffffff, result=0x00000000)
|
||||
test_mul_3 = test_op(Funct3.MUL, 0x00000000, 0x7fffffff, result=0x00000000)
|
||||
test_mul_4 = test_op(Funct3.MUL, 0x00000000, 0x80000000, result=0x00000000)
|
||||
|
||||
test_mul_5 = test_op(Funct3.MUL, 0x00000001, 0x00000000, result=0x00000000)
|
||||
test_mul_6 = test_op(Funct3.MUL, 0x00000001, 0x00000001, result=0x00000001)
|
||||
test_mul_7 = test_op(Funct3.MUL, 0x00000001, 0xffffffff, result=0xffffffff)
|
||||
test_mul_8 = test_op(Funct3.MUL, 0x00000001, 0x7fffffff, result=0x7fffffff)
|
||||
test_mul_9 = test_op(Funct3.MUL, 0x00000001, 0x80000000, result=0x80000000)
|
||||
|
||||
test_mul_10 = test_op(Funct3.MUL, 0xffffffff, 0x00000000, result=0x00000000)
|
||||
test_mul_11 = test_op(Funct3.MUL, 0xffffffff, 0x00000001, result=0xffffffff)
|
||||
test_mul_12 = test_op(Funct3.MUL, 0xffffffff, 0xffffffff, result=0x00000001)
|
||||
test_mul_13 = test_op(Funct3.MUL, 0xffffffff, 0x7fffffff, result=0x80000001)
|
||||
test_mul_14 = test_op(Funct3.MUL, 0xffffffff, 0x80000000, result=0x80000000)
|
||||
|
||||
test_mul_15 = test_op(Funct3.MUL, 0x7fffffff, 0x00000000, result=0x00000000)
|
||||
test_mul_16 = test_op(Funct3.MUL, 0x7fffffff, 0x00000001, result=0x7fffffff)
|
||||
test_mul_17 = test_op(Funct3.MUL, 0x7fffffff, 0xffffffff, result=0x80000001)
|
||||
test_mul_18 = test_op(Funct3.MUL, 0x7fffffff, 0x7fffffff, result=0x00000001)
|
||||
test_mul_19 = test_op(Funct3.MUL, 0x7fffffff, 0x80000000, result=0x80000000)
|
||||
|
||||
test_mul_20 = test_op(Funct3.MUL, 0x80000000, 0x00000000, result=0x00000000)
|
||||
test_mul_21 = test_op(Funct3.MUL, 0x80000000, 0x00000001, result=0x80000000)
|
||||
test_mul_22 = test_op(Funct3.MUL, 0x80000000, 0xffffffff, result=0x80000000)
|
||||
test_mul_23 = test_op(Funct3.MUL, 0x80000000, 0x7fffffff, result=0x80000000)
|
||||
test_mul_24 = test_op(Funct3.MUL, 0x80000000, 0x80000000, result=0x00000000)
|
||||
|
||||
# MULH ---------------------------------------------------------------------------
|
||||
|
||||
test_mulh_0 = test_op(Funct3.MULH, 0x00000000, 0x00000000, result=0x00000000)
|
||||
test_mulh_1 = test_op(Funct3.MULH, 0x00000000, 0x00000001, result=0x00000000)
|
||||
test_mulh_2 = test_op(Funct3.MULH, 0x00000000, 0xffffffff, result=0x00000000)
|
||||
test_mulh_3 = test_op(Funct3.MULH, 0x00000000, 0x7fffffff, result=0x00000000)
|
||||
test_mulh_4 = test_op(Funct3.MULH, 0x00000000, 0x80000000, result=0x00000000)
|
||||
|
||||
test_mulh_5 = test_op(Funct3.MULH, 0x00000001, 0x00000000, result=0x00000000)
|
||||
test_mulh_6 = test_op(Funct3.MULH, 0x00000001, 0x00000001, result=0x00000000)
|
||||
test_mulh_7 = test_op(Funct3.MULH, 0x00000001, 0xffffffff, result=0xffffffff)
|
||||
test_mulh_8 = test_op(Funct3.MULH, 0x00000001, 0x7fffffff, result=0x00000000)
|
||||
test_mulh_9 = test_op(Funct3.MULH, 0x00000001, 0x80000000, result=0xffffffff)
|
||||
|
||||
test_mulh_10 = test_op(Funct3.MULH, 0xffffffff, 0x00000000, result=0x00000000)
|
||||
test_mulh_11 = test_op(Funct3.MULH, 0xffffffff, 0x00000001, result=0xffffffff)
|
||||
test_mulh_12 = test_op(Funct3.MULH, 0xffffffff, 0xffffffff, result=0x00000000)
|
||||
test_mulh_13 = test_op(Funct3.MULH, 0xffffffff, 0x7fffffff, result=0xffffffff)
|
||||
test_mulh_14 = test_op(Funct3.MULH, 0xffffffff, 0x80000000, result=0x00000000)
|
||||
|
||||
test_mulh_15 = test_op(Funct3.MULH, 0x7fffffff, 0x00000000, result=0x00000000)
|
||||
test_mulh_16 = test_op(Funct3.MULH, 0x7fffffff, 0x00000001, result=0x00000000)
|
||||
test_mulh_17 = test_op(Funct3.MULH, 0x7fffffff, 0xffffffff, result=0xffffffff)
|
||||
test_mulh_18 = test_op(Funct3.MULH, 0x7fffffff, 0x7fffffff, result=0x3fffffff)
|
||||
test_mulh_19 = test_op(Funct3.MULH, 0x7fffffff, 0x80000000, result=0xc0000000)
|
||||
|
||||
test_mulh_20 = test_op(Funct3.MULH, 0x80000000, 0x00000000, result=0x00000000)
|
||||
test_mulh_21 = test_op(Funct3.MULH, 0x80000000, 0x00000001, result=0xffffffff)
|
||||
test_mulh_22 = test_op(Funct3.MULH, 0x80000000, 0xffffffff, result=0x00000000)
|
||||
test_mulh_23 = test_op(Funct3.MULH, 0x80000000, 0x7fffffff, result=0xc0000000)
|
||||
test_mulh_24 = test_op(Funct3.MULH, 0x80000000, 0x80000000, result=0x40000000)
|
||||
|
||||
# MULHSU -------------------------------------------------------------------------
|
||||
|
||||
test_mulhsu_0 = test_op(Funct3.MULHSU, 0x00000000, 0x00000000, result=0x00000000)
|
||||
test_mulhsu_1 = test_op(Funct3.MULHSU, 0x00000000, 0x00000001, result=0x00000000)
|
||||
test_mulhsu_2 = test_op(Funct3.MULHSU, 0x00000000, 0xffffffff, result=0x00000000)
|
||||
test_mulhsu_3 = test_op(Funct3.MULHSU, 0x00000000, 0x7fffffff, result=0x00000000)
|
||||
test_mulhsu_4 = test_op(Funct3.MULHSU, 0x00000000, 0x80000000, result=0x00000000)
|
||||
|
||||
test_mulhsu_5 = test_op(Funct3.MULHSU, 0x00000001, 0x00000000, result=0x00000000)
|
||||
test_mulhsu_6 = test_op(Funct3.MULHSU, 0x00000001, 0x00000001, result=0x00000000)
|
||||
test_mulhsu_7 = test_op(Funct3.MULHSU, 0x00000001, 0xffffffff, result=0x00000000)
|
||||
test_mulhsu_8 = test_op(Funct3.MULHSU, 0x00000001, 0x7fffffff, result=0x00000000)
|
||||
test_mulhsu_9 = test_op(Funct3.MULHSU, 0x00000001, 0x80000000, result=0x00000000)
|
||||
|
||||
test_mulhsu_10 = test_op(Funct3.MULHSU, 0xffffffff, 0x00000000, result=0x00000000)
|
||||
test_mulhsu_11 = test_op(Funct3.MULHSU, 0xffffffff, 0x00000001, result=0xffffffff)
|
||||
test_mulhsu_12 = test_op(Funct3.MULHSU, 0xffffffff, 0xffffffff, result=0xffffffff)
|
||||
test_mulhsu_13 = test_op(Funct3.MULHSU, 0xffffffff, 0x7fffffff, result=0xffffffff)
|
||||
test_mulhsu_14 = test_op(Funct3.MULHSU, 0xffffffff, 0x80000000, result=0xffffffff)
|
||||
|
||||
test_mulhsu_15 = test_op(Funct3.MULHSU, 0x7fffffff, 0x00000000, result=0x00000000)
|
||||
test_mulhsu_16 = test_op(Funct3.MULHSU, 0x7fffffff, 0x00000001, result=0x00000000)
|
||||
test_mulhsu_17 = test_op(Funct3.MULHSU, 0x7fffffff, 0xffffffff, result=0x7ffffffe)
|
||||
test_mulhsu_18 = test_op(Funct3.MULHSU, 0x7fffffff, 0x7fffffff, result=0x3fffffff)
|
||||
test_mulhsu_19 = test_op(Funct3.MULHSU, 0x7fffffff, 0x80000000, result=0x3fffffff)
|
||||
|
||||
test_mulhsu_20 = test_op(Funct3.MULHSU, 0x80000000, 0x00000000, result=0x00000000)
|
||||
test_mulhsu_21 = test_op(Funct3.MULHSU, 0x80000000, 0x00000001, result=0xffffffff)
|
||||
test_mulhsu_22 = test_op(Funct3.MULHSU, 0x80000000, 0xffffffff, result=0x80000000)
|
||||
test_mulhsu_23 = test_op(Funct3.MULHSU, 0x80000000, 0x7fffffff, result=0xc0000000)
|
||||
test_mulhsu_24 = test_op(Funct3.MULHSU, 0x80000000, 0x80000000, result=0xc0000000)
|
||||
|
||||
# MULHU --------------------------------------------------------------------------
|
||||
|
||||
test_mulhu_0 = test_op(Funct3.MULHU, 0x00000000, 0x00000000, result=0x00000000)
|
||||
test_mulhu_1 = test_op(Funct3.MULHU, 0x00000000, 0x00000001, result=0x00000000)
|
||||
test_mulhu_2 = test_op(Funct3.MULHU, 0x00000000, 0xffffffff, result=0x00000000)
|
||||
test_mulhu_3 = test_op(Funct3.MULHU, 0x00000000, 0x7fffffff, result=0x00000000)
|
||||
test_mulhu_4 = test_op(Funct3.MULHU, 0x00000000, 0x80000000, result=0x00000000)
|
||||
|
||||
test_mulhu_5 = test_op(Funct3.MULHU, 0x00000001, 0x00000000, result=0x00000000)
|
||||
test_mulhu_6 = test_op(Funct3.MULHU, 0x00000001, 0x00000001, result=0x00000000)
|
||||
test_mulhu_7 = test_op(Funct3.MULHU, 0x00000001, 0xffffffff, result=0x00000000)
|
||||
test_mulhu_8 = test_op(Funct3.MULHU, 0x00000001, 0x7fffffff, result=0x00000000)
|
||||
test_mulhu_9 = test_op(Funct3.MULHU, 0x00000001, 0x80000000, result=0x00000000)
|
||||
|
||||
test_mulhu_10 = test_op(Funct3.MULHU, 0xffffffff, 0x00000000, result=0x00000000)
|
||||
test_mulhu_11 = test_op(Funct3.MULHU, 0xffffffff, 0x00000001, result=0x00000000)
|
||||
test_mulhu_12 = test_op(Funct3.MULHU, 0xffffffff, 0xffffffff, result=0xfffffffe)
|
||||
test_mulhu_13 = test_op(Funct3.MULHU, 0xffffffff, 0x7fffffff, result=0x7ffffffe)
|
||||
test_mulhu_14 = test_op(Funct3.MULHU, 0xffffffff, 0x80000000, result=0x7fffffff)
|
||||
|
||||
test_mulhu_15 = test_op(Funct3.MULHU, 0x7fffffff, 0x00000000, result=0x00000000)
|
||||
test_mulhu_16 = test_op(Funct3.MULHU, 0x7fffffff, 0x00000001, result=0x00000000)
|
||||
test_mulhu_17 = test_op(Funct3.MULHU, 0x7fffffff, 0xffffffff, result=0x7ffffffe)
|
||||
test_mulhu_18 = test_op(Funct3.MULHU, 0x7fffffff, 0x7fffffff, result=0x3fffffff)
|
||||
test_mulhu_19 = test_op(Funct3.MULHU, 0x7fffffff, 0x80000000, result=0x3fffffff)
|
||||
|
||||
test_mulhu_20 = test_op(Funct3.MULHU, 0x80000000, 0x00000000, result=0x00000000)
|
||||
test_mulhu_21 = test_op(Funct3.MULHU, 0x80000000, 0x00000001, result=0x00000000)
|
||||
test_mulhu_22 = test_op(Funct3.MULHU, 0x80000000, 0xffffffff, result=0x7fffffff)
|
||||
test_mulhu_23 = test_op(Funct3.MULHU, 0x80000000, 0x7fffffff, result=0x3fffffff)
|
||||
test_mulhu_24 = test_op(Funct3.MULHU, 0x80000000, 0x80000000, result=0x40000000)
|
||||
0
cores/minerva/minerva/units/__init__.py
Normal file
0
cores/minerva/minerva/units/__init__.py
Normal file
31
cores/minerva/minerva/units/adder.py
Normal file
31
cores/minerva/minerva/units/adder.py
Normal file
@ -0,0 +1,31 @@
|
||||
from nmigen import *
|
||||
|
||||
|
||||
__all__ = ["Adder"]
|
||||
|
||||
|
||||
class Adder(Elaboratable):
|
||||
def __init__(self):
|
||||
self.sub = Signal()
|
||||
self.src1 = Signal(32)
|
||||
self.src2 = Signal(32)
|
||||
|
||||
self.result = Signal(32)
|
||||
self.carry = Signal()
|
||||
self.overflow = Signal()
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
with m.If(self.sub):
|
||||
m.d.comb += [
|
||||
Cat(self.result, self.carry).eq(self.src1 - self.src2),
|
||||
self.overflow.eq((self.src1[-1] != self.src2[-1]) & (self.result[-1] == self.src2[-1]))
|
||||
]
|
||||
with m.Else():
|
||||
m.d.comb += [
|
||||
Cat(self.result, self.carry).eq(self.src1 + self.src2),
|
||||
self.overflow.eq(~self.src1[-1] & self.src2[-1] & self.result[-1])
|
||||
]
|
||||
|
||||
return m
|
||||
36
cores/minerva/minerva/units/compare.py
Normal file
36
cores/minerva/minerva/units/compare.py
Normal file
@ -0,0 +1,36 @@
|
||||
from nmigen import *
|
||||
|
||||
from ..isa import Funct3
|
||||
|
||||
|
||||
__all__ = ["CompareUnit"]
|
||||
|
||||
|
||||
class CompareUnit(Elaboratable):
|
||||
def __init__(self):
|
||||
self.op = Signal(3)
|
||||
self.zero = Signal()
|
||||
self.negative = Signal()
|
||||
self.overflow = Signal()
|
||||
self.carry = Signal()
|
||||
|
||||
self.condition_met = Signal()
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
with m.Switch(self.op):
|
||||
with m.Case(Funct3.BEQ):
|
||||
m.d.comb += self.condition_met.eq(self.zero)
|
||||
with m.Case(Funct3.BNE):
|
||||
m.d.comb += self.condition_met.eq(~self.zero)
|
||||
with m.Case(Funct3.BLT):
|
||||
m.d.comb += self.condition_met.eq(~self.zero & (self.negative != self.overflow))
|
||||
with m.Case(Funct3.BGE):
|
||||
m.d.comb += self.condition_met.eq(self.negative == self.overflow)
|
||||
with m.Case(Funct3.BLTU):
|
||||
m.d.comb += self.condition_met.eq(~self.zero & self.carry)
|
||||
with m.Case(Funct3.BGEU):
|
||||
m.d.comb += self.condition_met.eq(~self.carry)
|
||||
|
||||
return m
|
||||
1
cores/minerva/minerva/units/debug/__init__.py
Normal file
1
cores/minerva/minerva/units/debug/__init__.py
Normal file
@ -0,0 +1 @@
|
||||
from .top import *
|
||||
212
cores/minerva/minerva/units/debug/controller.py
Normal file
212
cores/minerva/minerva/units/debug/controller.py
Normal file
@ -0,0 +1,212 @@
|
||||
from nmigen import *
|
||||
from nmigen.lib.coding import PriorityEncoder
|
||||
|
||||
from ...csr import *
|
||||
from ...isa import *
|
||||
from ...wishbone import wishbone_layout
|
||||
from .dmi import DebugReg, Command, Error, Version, cmd_access_reg_layout
|
||||
|
||||
|
||||
__all__ = ["DebugController"]
|
||||
|
||||
|
||||
class HaltCause:
|
||||
EBREAK = 1
|
||||
TRIGGER = 0
|
||||
HALTREQ = 3
|
||||
STEP = 4
|
||||
RESET_HALTREQ = 2
|
||||
|
||||
|
||||
cause_map = [2, 1, 5, 3, 4]
|
||||
|
||||
|
||||
class DebugController(Elaboratable):
|
||||
def __init__(self, debugrf):
|
||||
self.dcsr_we = Signal()
|
||||
self.dcsr_w = Record((fname, shape) for (fname, shape, mode) in dcsr_layout)
|
||||
self.dcsr_r = Record.like(self.dcsr_w)
|
||||
self.dpc_we = Signal()
|
||||
self.dpc_w = Signal(32)
|
||||
|
||||
self.dmstatus = debugrf.reg_port(DebugReg.DMSTATUS)
|
||||
self.dmcontrol = debugrf.reg_port(DebugReg.DMCONTROL)
|
||||
self.hartinfo = debugrf.reg_port(DebugReg.HARTINFO)
|
||||
self.abstractcs = debugrf.reg_port(DebugReg.ABSTRACTCS)
|
||||
self.command = debugrf.reg_port(DebugReg.COMMAND)
|
||||
self.data0 = debugrf.reg_port(DebugReg.DATA0)
|
||||
self.haltsum0 = debugrf.reg_port(DebugReg.HALTSUM0)
|
||||
|
||||
self.trigger_haltreq = Signal()
|
||||
|
||||
self.x_pc = Signal(32)
|
||||
self.x_ebreak = Signal()
|
||||
self.x_stall = Signal()
|
||||
|
||||
self.m_branch_taken = Signal()
|
||||
self.m_branch_target = Signal(32)
|
||||
self.m_mret = Signal()
|
||||
self.m_exception = Signal()
|
||||
self.m_pc = Signal(32)
|
||||
self.m_valid = Signal()
|
||||
self.mepc_r_base = Signal(30)
|
||||
self.mtvec_r_base = Signal(30)
|
||||
|
||||
self.halt = Signal()
|
||||
self.halted = Signal()
|
||||
self.killall = Signal()
|
||||
self.resumereq = Signal()
|
||||
self.resumeack = Signal()
|
||||
|
||||
self.gprf_addr = Signal(5)
|
||||
self.gprf_re = Signal()
|
||||
self.gprf_dat_r = Signal(32)
|
||||
self.gprf_we = Signal()
|
||||
self.gprf_dat_w = Signal(32)
|
||||
|
||||
self.csrf_addr = Signal(12)
|
||||
self.csrf_re = Signal()
|
||||
self.csrf_dat_r = Signal(32)
|
||||
self.csrf_we = Signal()
|
||||
self.csrf_dat_w = Signal(32)
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
with m.If(self.dmcontrol.update):
|
||||
m.d.sync += [
|
||||
self.dmcontrol.w.dmactive.eq(self.dmcontrol.r.dmactive),
|
||||
self.dmcontrol.w.ndmreset.eq(self.dmcontrol.r.ndmreset),
|
||||
self.dmcontrol.w.hartselhi.eq(self.dmcontrol.r.hartselhi),
|
||||
self.dmcontrol.w.hartsello.eq(self.dmcontrol.r.hartsello),
|
||||
self.dmcontrol.w.hasel.eq(self.dmcontrol.r.hasel),
|
||||
self.dmcontrol.w.hartreset.eq(self.dmcontrol.r.hartreset),
|
||||
self.dmcontrol.w.resumereq.eq(self.dmcontrol.r.resumereq),
|
||||
]
|
||||
|
||||
with m.If(self.abstractcs.update):
|
||||
m.d.sync += self.abstractcs.w.cmderr.eq(self.abstractcs.r.cmderr)
|
||||
|
||||
with m.If(self.data0.update):
|
||||
m.d.sync += self.data0.w.eq(self.data0.r)
|
||||
|
||||
m.d.comb += [
|
||||
self.dmstatus.w.version.eq(Version.V013),
|
||||
self.dmstatus.w.authenticated.eq(1),
|
||||
self.resumereq.eq(self.dmcontrol.w.resumereq),
|
||||
self.haltsum0.w[0].eq(self.dmstatus.w.allhalted),
|
||||
]
|
||||
|
||||
m_breakpoint = Signal()
|
||||
with m.If(~self.x_stall):
|
||||
m.d.comb += m_breakpoint.eq(self.x_ebreak & self.dcsr_r.ebreakm)
|
||||
|
||||
halt_pe = m.submodules.halt_pe = PriorityEncoder(5)
|
||||
m.d.comb += [
|
||||
halt_pe.i[HaltCause.EBREAK].eq(m_breakpoint & self.m_valid),
|
||||
halt_pe.i[HaltCause.TRIGGER].eq(self.trigger_haltreq),
|
||||
halt_pe.i[HaltCause.HALTREQ].eq(self.dmcontrol.r.haltreq),
|
||||
halt_pe.i[HaltCause.STEP].eq(self.dcsr_r.step & self.m_valid),
|
||||
]
|
||||
|
||||
with m.FSM():
|
||||
with m.State("RUN"):
|
||||
m.d.comb += self.dmstatus.w.allrunning.eq(1)
|
||||
m.d.comb += self.dmstatus.w.anyrunning.eq(1)
|
||||
with m.If(~halt_pe.n):
|
||||
m.d.sync += self.halt.eq(1)
|
||||
m.d.comb += [
|
||||
self.dcsr_we.eq(1),
|
||||
self.dcsr_w.eq(self.dcsr_r),
|
||||
self.dcsr_w.cause.eq(Array(cause_map)[halt_pe.o]),
|
||||
self.dcsr_w.stepie.eq(1)
|
||||
]
|
||||
m.d.comb += self.dpc_we.eq(1)
|
||||
with m.If(halt_pe.o == HaltCause.EBREAK):
|
||||
m.d.comb += self.dpc_w.eq(self.m_pc)
|
||||
with m.Elif(self.m_exception & self.m_valid):
|
||||
m.d.comb += self.dpc_w.eq(self.mtvec_r_base << 2)
|
||||
with m.Elif(self.m_mret & self.m_valid):
|
||||
m.d.comb += self.dpc_w.eq(self.mepc_r_base << 2)
|
||||
with m.Elif(self.m_branch_taken & self.m_valid):
|
||||
m.d.comb += self.dpc_w.eq(self.m_branch_target)
|
||||
with m.Else():
|
||||
m.d.comb += self.dpc_w.eq(self.x_pc)
|
||||
m.next = "HALTING"
|
||||
|
||||
with m.State("HALTING"):
|
||||
with m.If(self.halted):
|
||||
m.d.comb += self.killall.eq(1)
|
||||
m.d.sync += self.dmstatus.w.allhalted.eq(1)
|
||||
m.d.sync += self.dmstatus.w.anyhalted.eq(1)
|
||||
m.next = "WAIT"
|
||||
|
||||
with m.State("WAIT"):
|
||||
with m.If(self.dmcontrol.w.resumereq):
|
||||
m.next = "RESUME"
|
||||
with m.Elif(self.command.update):
|
||||
m.d.sync += self.abstractcs.w.busy.eq(1)
|
||||
m.next = "COMMAND:START"
|
||||
|
||||
with m.State("RESUME"):
|
||||
with m.If(self.resumeack):
|
||||
m.d.sync += [
|
||||
self.dmcontrol.w.resumereq.eq(0),
|
||||
self.dmstatus.w.allresumeack.eq(1),
|
||||
self.dmstatus.w.anyresumeack.eq(1),
|
||||
self.halt.eq(0),
|
||||
self.dmstatus.w.allhalted.eq(0),
|
||||
self.dmstatus.w.anyhalted.eq(0),
|
||||
]
|
||||
m.next = "RUN"
|
||||
|
||||
with m.State("COMMAND:START"):
|
||||
with m.Switch(self.command.r.cmdtype):
|
||||
with m.Case(Command.ACCESS_REG):
|
||||
control = Record(cmd_access_reg_layout)
|
||||
m.d.comb += control.eq(self.command.r.control)
|
||||
m.d.comb += self.gprf_addr.eq(control.regno)
|
||||
m.next = "COMMAND:ACCESS-REG"
|
||||
with m.Case():
|
||||
m.d.sync += self.abstractcs.w.cmderr.eq(Error.UNSUPPORTED)
|
||||
m.next = "COMMAND:DONE"
|
||||
|
||||
with m.State("COMMAND:ACCESS-REG"):
|
||||
control = Record(cmd_access_reg_layout)
|
||||
m.d.comb += control.eq(self.command.r.control)
|
||||
with m.If(control.postexec | (control.aarsize != 2) | control.aarpostincrement):
|
||||
# Unsupported parameters.
|
||||
m.d.sync += self.abstractcs.w.cmderr.eq(Error.EXCEPTION)
|
||||
with m.Elif(control.regno.matches("0000------------")):
|
||||
with m.If(control.transfer):
|
||||
m.d.comb += self.csrf_addr.eq(control.regno)
|
||||
with m.If(control.write):
|
||||
m.d.comb += [
|
||||
self.csrf_we.eq(1),
|
||||
self.csrf_dat_w.eq(self.data0.r)
|
||||
]
|
||||
with m.Else():
|
||||
m.d.comb += self.csrf_re.eq(1)
|
||||
m.d.sync += self.data0.w.eq(self.csrf_dat_r)
|
||||
m.d.sync += self.abstractcs.w.cmderr.eq(Error.NONE)
|
||||
with m.Elif(control.regno.matches("00010000000-----")):
|
||||
with m.If(control.transfer):
|
||||
m.d.comb += self.gprf_addr.eq(control.regno)
|
||||
with m.If(control.write):
|
||||
m.d.comb += [
|
||||
self.gprf_we.eq(1),
|
||||
self.gprf_dat_w.eq(self.data0.r)
|
||||
]
|
||||
with m.Else():
|
||||
m.d.sync += self.data0.w.eq(self.gprf_dat_r)
|
||||
m.d.sync += self.abstractcs.w.cmderr.eq(Error.NONE)
|
||||
with m.Else():
|
||||
# Unknown register number.
|
||||
m.d.sync += self.abstractcs.w.cmderr.eq(Error.EXCEPTION)
|
||||
m.next = "COMMAND:DONE"
|
||||
|
||||
with m.State("COMMAND:DONE"):
|
||||
m.d.sync += self.abstractcs.w.busy.eq(0)
|
||||
m.next = "WAIT"
|
||||
|
||||
return m
|
||||
144
cores/minerva/minerva/units/debug/dmi.py
Normal file
144
cores/minerva/minerva/units/debug/dmi.py
Normal file
@ -0,0 +1,144 @@
|
||||
from enum import Enum
|
||||
|
||||
|
||||
class Version:
|
||||
NONE = 0
|
||||
V011 = 1
|
||||
V013 = 2
|
||||
OTHER = 15
|
||||
|
||||
|
||||
class Command:
|
||||
ACCESS_REG = 0
|
||||
QUICK_ACCESS = 1
|
||||
ACCESS_MEM = 2
|
||||
|
||||
|
||||
class Error:
|
||||
NONE = 0
|
||||
BUSY = 1
|
||||
UNSUPPORTED = 2
|
||||
EXCEPTION = 3
|
||||
HALT_RESUME = 4
|
||||
|
||||
|
||||
RegMode = Enum("RegMode", ("R", "W", "W1", "RW", "RW1C", "WARL"))
|
||||
|
||||
|
||||
class DmiOp:
|
||||
NOP = 0
|
||||
READ = 1
|
||||
WRITE = 2
|
||||
|
||||
|
||||
# Debug registers
|
||||
|
||||
class DebugReg:
|
||||
DATA0 = 0x04
|
||||
DMCONTROL = 0x10
|
||||
DMSTATUS = 0x11
|
||||
HARTINFO = 0x12
|
||||
HALTSUM1 = 0x13
|
||||
ABSTRACTCS = 0x16
|
||||
COMMAND = 0x17
|
||||
PROGBUF0 = 0x20
|
||||
HALTSUM2 = 0x34
|
||||
HALTSUM3 = 0x35
|
||||
SBCS = 0x38
|
||||
SBADDRESS0 = 0x39
|
||||
SBDATA0 = 0x3c
|
||||
HALTSUM0 = 0x40
|
||||
|
||||
|
||||
dmstatus_layout = [
|
||||
("version", 4, RegMode.R, Version.V013),
|
||||
("confstrptrvalid", 1, RegMode.R, False),
|
||||
("hasresethaltreq", 1, RegMode.R, False),
|
||||
("authbusy", 1, RegMode.R, False),
|
||||
("authenticated", 1, RegMode.R, True),
|
||||
("anyhalted", 1, RegMode.R, False),
|
||||
("allhalted", 1, RegMode.R, False),
|
||||
("anyrunning", 1, RegMode.R, False),
|
||||
("allrunning", 1, RegMode.R, False),
|
||||
("anyunavail", 1, RegMode.R, False),
|
||||
("allunavail", 1, RegMode.R, False),
|
||||
("anynonexistent", 1, RegMode.R, False),
|
||||
("allnonexistent", 1, RegMode.R, False),
|
||||
("anyresumeack", 1, RegMode.R, False),
|
||||
("allresumeack", 1, RegMode.R, False),
|
||||
("anyhavereset", 1, RegMode.R, False),
|
||||
("allhavereset", 1, RegMode.R, False),
|
||||
("zero0", 2, RegMode.R, 0),
|
||||
("impebreak", 1, RegMode.R, False),
|
||||
("zero1", 9, RegMode.R, 0)
|
||||
]
|
||||
|
||||
|
||||
dmcontrol_layout = [
|
||||
("dmactive", 1, RegMode.RW, False),
|
||||
("ndmreset", 1, RegMode.RW, False),
|
||||
("clrresethaltreq", 1, RegMode.W1, False),
|
||||
("setresethaltreq", 1, RegMode.W1, False),
|
||||
("zero0", 2, RegMode.R, 0),
|
||||
("hartselhi", 10, RegMode.R, 0),
|
||||
("hartsello", 10, RegMode.R, 0),
|
||||
("hasel", 1, RegMode.RW, False),
|
||||
("zero1", 1, RegMode.R, 0),
|
||||
("ackhavereset", 1, RegMode.W1, False),
|
||||
("hartreset", 1, RegMode.RW, False),
|
||||
("resumereq", 1, RegMode.W1, False),
|
||||
("haltreq", 1, RegMode.W, False)
|
||||
]
|
||||
|
||||
|
||||
abstractcs_layout = [
|
||||
("datacount", 4, RegMode.R, 1),
|
||||
("zero0", 4, RegMode.R, 0),
|
||||
("cmderr", 3, RegMode.RW1C, 0),
|
||||
("zero1", 1, RegMode.R, 0),
|
||||
("busy", 1, RegMode.R, False),
|
||||
("zero2", 11, RegMode.R, 0),
|
||||
("progbufsize", 5, RegMode.R, 0),
|
||||
("zero3", 3, RegMode.R, 0)
|
||||
]
|
||||
|
||||
|
||||
cmd_access_reg_layout = [
|
||||
("regno", 16),
|
||||
("write", 1),
|
||||
("transfer", 1),
|
||||
("postexec", 1),
|
||||
("aarpostincrement", 1),
|
||||
("aarsize", 3),
|
||||
("zero0", 1),
|
||||
]
|
||||
|
||||
|
||||
command_layout = [
|
||||
("control", 24, RegMode.W, 0),
|
||||
("cmdtype", 8, RegMode.W, Command.ACCESS_REG)
|
||||
]
|
||||
|
||||
|
||||
sbcs_layout = [
|
||||
("sbaccess8", 1, RegMode.R, True),
|
||||
("sbaccess16", 1, RegMode.R, True),
|
||||
("sbaccess32", 1, RegMode.R, True),
|
||||
("sbaccess64", 1, RegMode.R, False),
|
||||
("sbaccess128", 1, RegMode.R, False),
|
||||
("sbasize", 7, RegMode.R, 32),
|
||||
("sberror", 3, RegMode.RW1C, 0),
|
||||
("sbreadondata", 1, RegMode.RW, False),
|
||||
("sbautoincrement", 1, RegMode.RW, False),
|
||||
("sbaccess", 3, RegMode.RW, 2),
|
||||
("sbreadonaddr", 1, RegMode.RW, False),
|
||||
("sbbusy", 1, RegMode.R, False),
|
||||
("sbbusyerror", 1, RegMode.RW1C, False),
|
||||
("zero0", 6, RegMode.R, 0),
|
||||
("sbversion", 3, RegMode.R, 1)
|
||||
]
|
||||
|
||||
|
||||
flat_layout = [
|
||||
("value", 32, RegMode.RW, 0)
|
||||
]
|
||||
41
cores/minerva/minerva/units/debug/jtag.py
Normal file
41
cores/minerva/minerva/units/debug/jtag.py
Normal file
@ -0,0 +1,41 @@
|
||||
from nmigen.hdl.rec import *
|
||||
|
||||
|
||||
__all__ = ["jtag_layout", "JTAGReg", "dtmcs_layout", "dmi_layout"]
|
||||
|
||||
|
||||
jtag_layout = [
|
||||
("tck", 1, DIR_FANIN),
|
||||
("tdi", 1, DIR_FANIN),
|
||||
("tdo", 1, DIR_FANOUT),
|
||||
("tms", 1, DIR_FANIN),
|
||||
("trst", 1, DIR_FANIN) # TODO
|
||||
]
|
||||
|
||||
|
||||
class JTAGReg:
|
||||
BYPASS = 0x00
|
||||
IDCODE = 0x01
|
||||
DTMCS = 0x10
|
||||
DMI = 0x11
|
||||
|
||||
|
||||
# JTAG register layouts
|
||||
|
||||
dtmcs_layout = [
|
||||
("version", 4),
|
||||
("abits", 6),
|
||||
("dmistat", 2),
|
||||
("idle", 3),
|
||||
("zero0", 1),
|
||||
("dmireset", 1),
|
||||
("dmihardreset", 1),
|
||||
("zero1", 14)
|
||||
]
|
||||
|
||||
|
||||
dmi_layout = [
|
||||
("op", 2),
|
||||
("data", 32),
|
||||
("addr", 7),
|
||||
]
|
||||
95
cores/minerva/minerva/units/debug/regfile.py
Normal file
95
cores/minerva/minerva/units/debug/regfile.py
Normal file
@ -0,0 +1,95 @@
|
||||
from nmigen import *
|
||||
from nmigen.hdl.rec import *
|
||||
|
||||
from .dmi import *
|
||||
|
||||
|
||||
__all__ = ["DebugRegisterFile"]
|
||||
|
||||
|
||||
class DmiOp:
|
||||
NOP = 0
|
||||
READ = 1
|
||||
WRITE = 2
|
||||
|
||||
|
||||
reg_map = {
|
||||
DebugReg.DMSTATUS: dmstatus_layout,
|
||||
DebugReg.DMCONTROL: dmcontrol_layout,
|
||||
DebugReg.HARTINFO: flat_layout,
|
||||
DebugReg.ABSTRACTCS: abstractcs_layout,
|
||||
DebugReg.COMMAND: command_layout,
|
||||
DebugReg.SBCS: sbcs_layout,
|
||||
DebugReg.SBADDRESS0: flat_layout,
|
||||
DebugReg.SBDATA0: flat_layout,
|
||||
DebugReg.DATA0: flat_layout,
|
||||
DebugReg.HALTSUM0: flat_layout,
|
||||
DebugReg.HALTSUM1: flat_layout,
|
||||
}
|
||||
|
||||
|
||||
class DebugRegisterFile(Elaboratable):
|
||||
def __init__(self, dmi):
|
||||
self.dmi = dmi
|
||||
self.ports = dict()
|
||||
|
||||
def reg_port(self, addr, name=None, src_loc_at=0):
|
||||
if addr not in reg_map:
|
||||
raise ValueError("Unknown register {:x}.".format(addr))
|
||||
if addr in self.ports:
|
||||
raise ValueError("Register {:x} has already been allocated.".format(addr))
|
||||
layout = [f[:2] for f in reg_map[addr]]
|
||||
port = Record([("r", layout), ("w", layout), ("update", 1), ("capture", 1)],
|
||||
name=name, src_loc_at=1 + src_loc_at)
|
||||
for name, shape, mode, reset in reg_map[addr]:
|
||||
getattr(port.r, name).reset = reset
|
||||
getattr(port.w, name).reset = reset
|
||||
self.ports[addr] = port
|
||||
return port
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
def do_read(addr, port):
|
||||
rec = Record(port.w.layout)
|
||||
m.d.sync += self.dmi.r.data.eq(rec)
|
||||
for name, shape, mode, reset in reg_map[addr]:
|
||||
dst = getattr(rec, name)
|
||||
src = getattr(port.w, name)
|
||||
if mode in {RegMode.R, RegMode.RW, RegMode.RW1C}:
|
||||
m.d.comb += dst.eq(src)
|
||||
else:
|
||||
m.d.comb += dst.eq(Const(0))
|
||||
m.d.sync += port.capture.eq(1)
|
||||
|
||||
def do_write(addr, port):
|
||||
rec = Record(port.r.layout)
|
||||
m.d.comb += rec.eq(self.dmi.w.data)
|
||||
for name, shape, mode, reset in reg_map[addr]:
|
||||
dst = getattr(port.r, name)
|
||||
src = getattr(rec, name)
|
||||
if mode in {RegMode.W, RegMode.RW}:
|
||||
m.d.sync += dst.eq(src)
|
||||
elif mode is RegMode.W1:
|
||||
m.d.sync += dst.eq(getattr(port.w, name) | src)
|
||||
elif mode is RegMode.RW1C:
|
||||
m.d.sync += dst.eq(getattr(port.w, name) & ~src)
|
||||
|
||||
m.d.sync += port.update.eq(1)
|
||||
|
||||
with m.If(self.dmi.update):
|
||||
with m.Switch(self.dmi.w.addr):
|
||||
for addr, port in self.ports.items():
|
||||
with m.Case(addr):
|
||||
with m.If(self.dmi.w.op == DmiOp.READ):
|
||||
do_read(addr, port)
|
||||
with m.Elif(self.dmi.w.op == DmiOp.WRITE):
|
||||
do_write(addr, port)
|
||||
|
||||
for port in self.ports.values():
|
||||
with m.If(port.update):
|
||||
m.d.sync += port.update.eq(0)
|
||||
with m.If(port.capture):
|
||||
m.d.sync += port.capture.eq(0)
|
||||
|
||||
return m
|
||||
136
cores/minerva/minerva/units/debug/top.py
Normal file
136
cores/minerva/minerva/units/debug/top.py
Normal file
@ -0,0 +1,136 @@
|
||||
from nmigen import *
|
||||
from nmigen.hdl.rec import *
|
||||
|
||||
|
||||
from ...csr import *
|
||||
from ...isa import *
|
||||
from ...wishbone import wishbone_layout
|
||||
from .controller import *
|
||||
from .jtag import *
|
||||
from .regfile import *
|
||||
from .wbmaster import *
|
||||
|
||||
|
||||
__all__ = ["DebugUnit"]
|
||||
|
||||
|
||||
jtag_regs = {
|
||||
JTAGReg.IDCODE: [("value", 32)],
|
||||
JTAGReg.DTMCS: dtmcs_layout,
|
||||
JTAGReg.DMI: dmi_layout
|
||||
}
|
||||
|
||||
|
||||
class DebugUnit(Elaboratable, AutoCSR):
|
||||
def __init__(self):
|
||||
self.jtag = Record(jtag_layout)
|
||||
self.dbus = Record(wishbone_layout)
|
||||
|
||||
self.trigger_haltreq = Signal()
|
||||
|
||||
self.x_ebreak = Signal()
|
||||
self.x_pc = Signal(32)
|
||||
self.x_stall = Signal()
|
||||
|
||||
self.m_branch_taken = Signal()
|
||||
self.m_branch_target = Signal(32)
|
||||
self.m_mret = Signal()
|
||||
self.m_exception = Signal()
|
||||
self.m_pc = Signal(32)
|
||||
self.m_valid = Signal()
|
||||
self.mepc_r_base = Signal(30)
|
||||
self.mtvec_r_base = Signal(30)
|
||||
|
||||
self.dcsr_step = Signal()
|
||||
self.dcsr_ebreakm = Signal()
|
||||
self.dpc_value = Signal(32)
|
||||
|
||||
self.halt = Signal()
|
||||
self.halted = Signal()
|
||||
self.killall = Signal()
|
||||
self.resumereq = Signal()
|
||||
self.resumeack = Signal()
|
||||
|
||||
self.dbus_busy = Signal()
|
||||
|
||||
self.csrf_addr = Signal(12)
|
||||
self.csrf_re = Signal()
|
||||
self.csrf_dat_r = Signal(32)
|
||||
self.csrf_we = Signal()
|
||||
self.csrf_dat_w = Signal(32)
|
||||
|
||||
self.gprf_addr = Signal(5)
|
||||
self.gprf_re = Signal()
|
||||
self.gprf_dat_r = Signal(32)
|
||||
self.gprf_we = Signal()
|
||||
self.gprf_dat_w = Signal(32)
|
||||
|
||||
self.dcsr = CSR(0x7b0, dcsr_layout)
|
||||
self.dpc = CSR(0x7b1, flat_layout)
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
from jtagtap import JTAGTap
|
||||
tap = m.submodules.tap = JTAGTap(jtag_regs)
|
||||
regfile = m.submodules.regfile = DebugRegisterFile(tap.regs[JTAGReg.DMI])
|
||||
controller = m.submodules.controller = DebugController(regfile)
|
||||
wbmaster = m.submodules.wbmaster = DebugWishboneMaster(regfile)
|
||||
|
||||
m.d.comb += [
|
||||
tap.port.connect(self.jtag),
|
||||
tap.regs[JTAGReg.IDCODE].r.eq(0x10e31913), # Usurpate a Spike core for now.
|
||||
tap.regs[JTAGReg.DTMCS].r.eq(0x71) # (abits=7, version=1) TODO
|
||||
]
|
||||
|
||||
self.dcsr.r.xdebugver.reset = 4 # Use debug spec v0.13
|
||||
with m.If(self.dcsr.we):
|
||||
m.d.sync += self.dcsr.r.eq(self.dcsr.w)
|
||||
with m.If(controller.dcsr_we):
|
||||
m.d.sync += self.dcsr.r.eq(controller.dcsr_w)
|
||||
|
||||
with m.If(controller.dpc_we):
|
||||
m.d.sync += self.dpc.r.eq(controller.dpc_w)
|
||||
|
||||
m.d.comb += [
|
||||
controller.dcsr_r.eq(self.dcsr.r),
|
||||
controller.trigger_haltreq.eq(self.trigger_haltreq),
|
||||
|
||||
controller.x_ebreak.eq(self.x_ebreak),
|
||||
controller.x_pc.eq(self.x_pc),
|
||||
controller.x_stall.eq(self.x_stall),
|
||||
|
||||
controller.m_branch_taken.eq(self.m_branch_taken),
|
||||
controller.m_branch_target.eq(self.m_branch_target),
|
||||
controller.m_pc.eq(self.m_pc),
|
||||
controller.m_valid.eq(self.m_valid),
|
||||
|
||||
self.halt.eq(controller.halt),
|
||||
controller.halted.eq(self.halted),
|
||||
self.killall.eq(controller.killall),
|
||||
self.resumereq.eq(controller.resumereq),
|
||||
controller.resumeack.eq(self.resumeack),
|
||||
|
||||
self.dcsr_step.eq(self.dcsr.r.step),
|
||||
self.dcsr_ebreakm.eq(self.dcsr.r.ebreakm),
|
||||
self.dpc_value.eq(self.dpc.r.value),
|
||||
|
||||
self.csrf_addr.eq(controller.csrf_addr),
|
||||
self.csrf_re.eq(controller.csrf_re),
|
||||
controller.csrf_dat_r.eq(self.csrf_dat_r),
|
||||
self.csrf_we.eq(controller.csrf_we),
|
||||
self.csrf_dat_w.eq(controller.csrf_dat_w),
|
||||
|
||||
self.gprf_addr.eq(controller.gprf_addr),
|
||||
self.gprf_re.eq(controller.gprf_re),
|
||||
controller.gprf_dat_r.eq(self.gprf_dat_r),
|
||||
self.gprf_we.eq(controller.gprf_we),
|
||||
self.gprf_dat_w.eq(controller.gprf_dat_w),
|
||||
]
|
||||
|
||||
m.d.comb += [
|
||||
wbmaster.bus.connect(self.dbus),
|
||||
self.dbus_busy.eq(wbmaster.dbus_busy)
|
||||
]
|
||||
|
||||
return m
|
||||
126
cores/minerva/minerva/units/debug/wbmaster.py
Normal file
126
cores/minerva/minerva/units/debug/wbmaster.py
Normal file
@ -0,0 +1,126 @@
|
||||
from functools import reduce
|
||||
from operator import or_
|
||||
|
||||
from nmigen import *
|
||||
from nmigen.hdl.rec import *
|
||||
|
||||
from ...wishbone import wishbone_layout
|
||||
from .dmi import *
|
||||
|
||||
|
||||
__all__ = ["BusError", "AccessSize", "DebugWishboneMaster"]
|
||||
|
||||
|
||||
class BusError:
|
||||
NONE = 0
|
||||
TIMEOUT = 1
|
||||
BAD_ADDRESS = 2
|
||||
MISALIGNED = 3
|
||||
BAD_SIZE = 4
|
||||
OTHER = 7
|
||||
|
||||
|
||||
class AccessSize:
|
||||
BYTE = 0
|
||||
HALF = 1
|
||||
WORD = 2
|
||||
|
||||
|
||||
class DebugWishboneMaster(Elaboratable):
|
||||
def __init__(self, debugrf):
|
||||
self.bus = Record(wishbone_layout)
|
||||
|
||||
self.dbus_busy = Signal()
|
||||
|
||||
self.sbcs = debugrf.reg_port(DebugReg.SBCS)
|
||||
self.sbaddress0 = debugrf.reg_port(DebugReg.SBADDRESS0)
|
||||
self.sbdata0 = debugrf.reg_port(DebugReg.SBDATA0)
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
addr = self.sbaddress0.w.value
|
||||
size = self.sbcs.r.sbaccess
|
||||
|
||||
width = Signal(6)
|
||||
m.d.comb += width.eq((1<<size)*8)
|
||||
|
||||
sbbusyerror = self.sbcs.w.sbbusyerror
|
||||
sberror = self.sbcs.w.sberror
|
||||
m.d.comb += self.dbus_busy.eq(self.sbcs.w.sbbusy)
|
||||
|
||||
m.d.comb += [
|
||||
self.sbcs.w.sbaccess8.eq(1),
|
||||
self.sbcs.w.sbaccess16.eq(1),
|
||||
self.sbcs.w.sbaccess32.eq(1),
|
||||
self.sbcs.w.sbasize.eq(32),
|
||||
self.sbcs.w.sbversion.eq(1)
|
||||
]
|
||||
|
||||
with m.If(self.sbcs.update):
|
||||
m.d.sync += [
|
||||
self.sbcs.w.sbbusyerror.eq(self.sbcs.r.sbbusyerror),
|
||||
self.sbcs.w.sberror.eq(self.sbcs.r.sberror)
|
||||
]
|
||||
|
||||
we = Signal()
|
||||
re = Signal()
|
||||
|
||||
with m.If(self.sbdata0.update):
|
||||
with m.If(self.sbcs.w.sbbusy):
|
||||
m.d.sync += self.sbcs.w.sbbusyerror.eq(1)
|
||||
with m.Else():
|
||||
m.d.sync += we.eq(~sberror.bool())
|
||||
|
||||
with m.If(self.sbdata0.capture):
|
||||
with m.If(self.sbcs.w.sbbusy):
|
||||
m.d.sync += self.sbcs.w.sbbusyerror.eq(1)
|
||||
with m.Else():
|
||||
m.d.sync += re.eq(self.sbcs.r.sbreadondata & ~sberror.bool())
|
||||
|
||||
with m.If(self.sbaddress0.update):
|
||||
with m.If(self.sbcs.w.sbbusy):
|
||||
m.d.sync += self.sbcs.w.sbbusyerror.eq(1)
|
||||
with m.Else():
|
||||
m.d.sync += [
|
||||
re.eq(self.sbcs.r.sbreadonaddr & ~sberror.bool()),
|
||||
self.sbaddress0.w.value.eq(self.sbaddress0.r.value)
|
||||
]
|
||||
|
||||
with m.FSM():
|
||||
with m.State("IDLE"):
|
||||
with m.If(we | re):
|
||||
m.d.sync += we.eq(0), re.eq(0)
|
||||
with m.If(size > AccessSize.WORD):
|
||||
m.d.sync += sberror.eq(BusError.BAD_SIZE)
|
||||
with m.Elif((addr & (1<<size)-1) != 0):
|
||||
m.d.sync += sberror.eq(BusError.MISALIGNED)
|
||||
with m.Else():
|
||||
m.d.sync += [
|
||||
self.bus.cyc.eq(1),
|
||||
self.bus.stb.eq(1),
|
||||
self.bus.adr.eq(addr[2:]),
|
||||
self.bus.we.eq(we),
|
||||
self.bus.sel.eq((1<<(1<<size))-1 << addr[:2]),
|
||||
self.bus.dat_w.eq((self.sbdata0.r & (1<<width)-1) << addr[:2]*8)
|
||||
]
|
||||
m.next = "BUSY"
|
||||
|
||||
with m.State("BUSY"):
|
||||
m.d.comb += self.sbcs.w.sbbusy.eq(1)
|
||||
with m.If(self.bus.ack | self.bus.err):
|
||||
m.d.sync += [
|
||||
self.bus.cyc.eq(0),
|
||||
self.bus.stb.eq(0),
|
||||
self.bus.we.eq(0),
|
||||
]
|
||||
with m.If(self.bus.err):
|
||||
m.d.sync += sberror.eq(BusError.OTHER)
|
||||
with m.Else():
|
||||
with m.If(~self.bus.we):
|
||||
m.d.sync += self.sbdata0.w.eq((self.bus.dat_r >> addr[:2]*8) & (1<<width)-1)
|
||||
with m.If(self.sbcs.r.sbautoincrement):
|
||||
m.d.sync += addr.eq(addr + (1<<size))
|
||||
m.next = "IDLE"
|
||||
|
||||
return m
|
||||
261
cores/minerva/minerva/units/decoder.py
Normal file
261
cores/minerva/minerva/units/decoder.py
Normal file
@ -0,0 +1,261 @@
|
||||
from functools import reduce
|
||||
from itertools import starmap
|
||||
from operator import or_
|
||||
|
||||
from nmigen import *
|
||||
|
||||
from ..isa import Opcode, Funct3, Funct7, Funct12
|
||||
|
||||
|
||||
__all__ = ["InstructionDecoder"]
|
||||
|
||||
|
||||
class Type:
|
||||
R = 0
|
||||
I = 1
|
||||
S = 2
|
||||
B = 3
|
||||
U = 4
|
||||
J = 5
|
||||
|
||||
|
||||
class InstructionDecoder(Elaboratable):
|
||||
def __init__(self, with_muldiv):
|
||||
self.with_muldiv = with_muldiv
|
||||
|
||||
self.instruction = Signal(32)
|
||||
|
||||
self.rd = Signal(5)
|
||||
self.rd_we = Signal()
|
||||
self.rs1 = Signal(5)
|
||||
self.rs1_re = Signal()
|
||||
self.rs2 = Signal(5)
|
||||
self.rs2_re = Signal()
|
||||
self.immediate = Signal((32, True))
|
||||
self.bypass_x = Signal()
|
||||
self.bypass_m = Signal()
|
||||
self.load = Signal()
|
||||
self.store = Signal()
|
||||
self.fence_i = Signal()
|
||||
self.adder = Signal()
|
||||
self.adder_sub = Signal()
|
||||
self.logic = Signal()
|
||||
self.multiply = Signal()
|
||||
self.divide = Signal()
|
||||
self.shift = Signal()
|
||||
self.direction = Signal()
|
||||
self.sext = Signal()
|
||||
self.lui = Signal()
|
||||
self.auipc = Signal()
|
||||
self.jump = Signal()
|
||||
self.branch = Signal()
|
||||
self.compare = Signal()
|
||||
self.csr = Signal()
|
||||
self.csr_we = Signal()
|
||||
self.privileged = Signal()
|
||||
self.ecall = Signal()
|
||||
self.ebreak = Signal()
|
||||
self.mret = Signal()
|
||||
self.funct3 = Signal(3)
|
||||
self.illegal = Signal()
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
opcode = Signal(5)
|
||||
funct3 = Signal(3)
|
||||
funct7 = Signal(7)
|
||||
funct12 = Signal(12)
|
||||
|
||||
iimm12 = Signal((12, True))
|
||||
simm12 = Signal((12, True))
|
||||
bimm12 = Signal((13, True))
|
||||
uimm20 = Signal(20)
|
||||
jimm20 = Signal((21, True))
|
||||
|
||||
insn = self.instruction
|
||||
fmt = Signal(range(Type.J + 1))
|
||||
|
||||
m.d.comb += [
|
||||
opcode.eq(insn[2:7]),
|
||||
funct3.eq(insn[12:15]),
|
||||
funct7.eq(insn[25:32]),
|
||||
funct12.eq(insn[20:32]),
|
||||
|
||||
iimm12.eq(insn[20:32]),
|
||||
simm12.eq(Cat(insn[7:12], insn[25:32])),
|
||||
bimm12.eq(Cat(0, insn[8:12], insn[25:31], insn[7], insn[31])),
|
||||
uimm20.eq(insn[12:32]),
|
||||
jimm20.eq(Cat(0, insn[21:31], insn[20], insn[12:20], insn[31])),
|
||||
]
|
||||
|
||||
with m.Switch(opcode):
|
||||
with m.Case(Opcode.LUI):
|
||||
m.d.comb += fmt.eq(Type.U)
|
||||
with m.Case(Opcode.AUIPC):
|
||||
m.d.comb += fmt.eq(Type.U)
|
||||
with m.Case(Opcode.JAL):
|
||||
m.d.comb += fmt.eq(Type.J)
|
||||
with m.Case(Opcode.JALR):
|
||||
m.d.comb += fmt.eq(Type.I)
|
||||
with m.Case(Opcode.BRANCH):
|
||||
m.d.comb += fmt.eq(Type.B)
|
||||
with m.Case(Opcode.LOAD):
|
||||
m.d.comb += fmt.eq(Type.I)
|
||||
with m.Case(Opcode.STORE):
|
||||
m.d.comb += fmt.eq(Type.S)
|
||||
with m.Case(Opcode.OP_IMM_32):
|
||||
m.d.comb += fmt.eq(Type.I)
|
||||
with m.Case(Opcode.OP_32):
|
||||
m.d.comb += fmt.eq(Type.R)
|
||||
with m.Case(Opcode.MISC_MEM):
|
||||
m.d.comb += fmt.eq(Type.I)
|
||||
with m.Case(Opcode.SYSTEM):
|
||||
m.d.comb += fmt.eq(Type.I)
|
||||
|
||||
with m.Switch(fmt):
|
||||
with m.Case(Type.I):
|
||||
m.d.comb += self.immediate.eq(iimm12)
|
||||
with m.Case(Type.S):
|
||||
m.d.comb += self.immediate.eq(simm12)
|
||||
with m.Case(Type.B):
|
||||
m.d.comb += self.immediate.eq(bimm12)
|
||||
with m.Case(Type.U):
|
||||
m.d.comb += self.immediate.eq(uimm20 << 12)
|
||||
with m.Case(Type.J):
|
||||
m.d.comb += self.immediate.eq(jimm20)
|
||||
|
||||
m.d.comb += [
|
||||
self.rd.eq(insn[7:12]),
|
||||
self.rs1.eq(insn[15:20]),
|
||||
self.rs2.eq(insn[20:25]),
|
||||
|
||||
self.rd_we.eq(reduce(or_, (fmt == T for T in (Type.R, Type.I, Type.U, Type.J)))),
|
||||
self.rs1_re.eq(reduce(or_, (fmt == T for T in (Type.R, Type.I, Type.S, Type.B)))),
|
||||
self.rs2_re.eq(reduce(or_, (fmt == T for T in (Type.R, Type.S, Type.B)))),
|
||||
|
||||
self.funct3.eq(funct3)
|
||||
]
|
||||
|
||||
def matcher(encodings):
|
||||
return reduce(or_, starmap(
|
||||
lambda opc, f3=None, f7=None, f12=None:
|
||||
(opcode == opc if opc is not None else 1) \
|
||||
& (funct3 == f3 if f3 is not None else 1) \
|
||||
& (funct7 == f7 if f7 is not None else 1) \
|
||||
& (funct12 == f12 if f12 is not None else 1),
|
||||
encodings))
|
||||
|
||||
m.d.comb += [
|
||||
self.compare.eq(matcher([
|
||||
(Opcode.OP_IMM_32, Funct3.SLT, None), # slti
|
||||
(Opcode.OP_IMM_32, Funct3.SLTU, None), # sltiu
|
||||
(Opcode.OP_32, Funct3.SLT, 0), # slt
|
||||
(Opcode.OP_32, Funct3.SLTU, 0) # sltu
|
||||
])),
|
||||
self.branch.eq(matcher([
|
||||
(Opcode.BRANCH, Funct3.BEQ, None), # beq
|
||||
(Opcode.BRANCH, Funct3.BNE, None), # bne
|
||||
(Opcode.BRANCH, Funct3.BLT, None), # blt
|
||||
(Opcode.BRANCH, Funct3.BGE, None), # bge
|
||||
(Opcode.BRANCH, Funct3.BLTU, None), # bltu
|
||||
(Opcode.BRANCH, Funct3.BGEU, None) # bgeu
|
||||
])),
|
||||
|
||||
self.adder.eq(matcher([
|
||||
(Opcode.OP_IMM_32, Funct3.ADD, None), # addi
|
||||
(Opcode.OP_32, Funct3.ADD, Funct7.ADD), # add
|
||||
(Opcode.OP_32, Funct3.ADD, Funct7.SUB) # sub
|
||||
])),
|
||||
self.adder_sub.eq(self.rs2_re & (funct7 == Funct7.SUB)),
|
||||
|
||||
self.logic.eq(matcher([
|
||||
(Opcode.OP_IMM_32, Funct3.XOR, None), # xori
|
||||
(Opcode.OP_IMM_32, Funct3.OR, None), # ori
|
||||
(Opcode.OP_IMM_32, Funct3.AND, None), # andi
|
||||
(Opcode.OP_32, Funct3.XOR, 0), # xor
|
||||
(Opcode.OP_32, Funct3.OR, 0), # or
|
||||
(Opcode.OP_32, Funct3.AND, 0) # and
|
||||
])),
|
||||
]
|
||||
|
||||
if self.with_muldiv:
|
||||
m.d.comb += [
|
||||
self.multiply.eq(matcher([
|
||||
(Opcode.OP_32, Funct3.MUL, Funct7.MULDIV), # mul
|
||||
(Opcode.OP_32, Funct3.MULH, Funct7.MULDIV), # mulh
|
||||
(Opcode.OP_32, Funct3.MULHSU, Funct7.MULDIV), # mulhsu
|
||||
(Opcode.OP_32, Funct3.MULHU, Funct7.MULDIV), # mulhu
|
||||
])),
|
||||
|
||||
self.divide.eq(matcher([
|
||||
(Opcode.OP_32, Funct3.DIV, Funct7.MULDIV), # div
|
||||
(Opcode.OP_32, Funct3.DIVU, Funct7.MULDIV), # divu
|
||||
(Opcode.OP_32, Funct3.REM, Funct7.MULDIV), # rem
|
||||
(Opcode.OP_32, Funct3.REMU, Funct7.MULDIV) # remu
|
||||
])),
|
||||
]
|
||||
|
||||
m.d.comb += [
|
||||
self.shift.eq(matcher([
|
||||
(Opcode.OP_IMM_32, Funct3.SLL, 0), # slli
|
||||
(Opcode.OP_IMM_32, Funct3.SR, Funct7.SRL), # srli
|
||||
(Opcode.OP_IMM_32, Funct3.SR, Funct7.SRA), # srai
|
||||
(Opcode.OP_32, Funct3.SLL, 0), # sll
|
||||
(Opcode.OP_32, Funct3.SR, Funct7.SRL), # srl
|
||||
(Opcode.OP_32, Funct3.SR, Funct7.SRA) # sra
|
||||
])),
|
||||
self.direction.eq(funct3 == Funct3.SR),
|
||||
self.sext.eq(funct7 == Funct7.SRA),
|
||||
|
||||
self.lui.eq(opcode == Opcode.LUI),
|
||||
self.auipc.eq(opcode == Opcode.AUIPC),
|
||||
|
||||
self.jump.eq(matcher([
|
||||
(Opcode.JAL, None), # jal
|
||||
(Opcode.JALR, 0) # jalr
|
||||
])),
|
||||
|
||||
self.load.eq(matcher([
|
||||
(Opcode.LOAD, Funct3.B), # lb
|
||||
(Opcode.LOAD, Funct3.BU), # lbu
|
||||
(Opcode.LOAD, Funct3.H), # lh
|
||||
(Opcode.LOAD, Funct3.HU), # lhu
|
||||
(Opcode.LOAD, Funct3.W) # lw
|
||||
])),
|
||||
self.store.eq(matcher([
|
||||
(Opcode.STORE, Funct3.B), # sb
|
||||
(Opcode.STORE, Funct3.H), # sh
|
||||
(Opcode.STORE, Funct3.W) # sw
|
||||
])),
|
||||
|
||||
self.fence_i.eq(matcher([
|
||||
(Opcode.MISC_MEM, Funct3.FENCEI) # fence.i
|
||||
])),
|
||||
|
||||
self.csr.eq(matcher([
|
||||
(Opcode.SYSTEM, Funct3.CSRRW), # csrrw
|
||||
(Opcode.SYSTEM, Funct3.CSRRS), # csrrs
|
||||
(Opcode.SYSTEM, Funct3.CSRRC), # csrrc
|
||||
(Opcode.SYSTEM, Funct3.CSRRWI), # csrrwi
|
||||
(Opcode.SYSTEM, Funct3.CSRRSI), # csrrsi
|
||||
(Opcode.SYSTEM, Funct3.CSRRCI) # csrrci
|
||||
])),
|
||||
self.csr_we.eq(~funct3[1] | (self.rs1 != 0)),
|
||||
|
||||
self.privileged.eq((opcode == Opcode.SYSTEM) & (funct3 == Funct3.PRIV)),
|
||||
self.ecall.eq(self.privileged & (funct12 == Funct12.ECALL)),
|
||||
self.ebreak.eq(self.privileged & (funct12 == Funct12.EBREAK)),
|
||||
self.mret.eq(self.privileged & (funct12 == Funct12.MRET)),
|
||||
|
||||
self.bypass_x.eq(self.adder | self.logic | self.lui | self.auipc | self.csr),
|
||||
self.bypass_m.eq(self.compare | self.divide | self.shift),
|
||||
|
||||
self.illegal.eq((self.instruction[:2] != 0b11) | ~reduce(or_, (
|
||||
self.compare, self.branch, self.adder, self.logic, self.multiply, self.divide, self.shift,
|
||||
self.lui, self.auipc, self.jump, self.load, self.store,
|
||||
self.csr, self.ecall, self.ebreak, self.mret, self.fence_i,
|
||||
)))
|
||||
]
|
||||
|
||||
return m
|
||||
144
cores/minerva/minerva/units/divider.py
Normal file
144
cores/minerva/minerva/units/divider.py
Normal file
@ -0,0 +1,144 @@
|
||||
from nmigen import *
|
||||
|
||||
from ..isa import Funct3
|
||||
|
||||
|
||||
__all__ = ["DividerInterface", "Divider", "DummyDivider"]
|
||||
|
||||
|
||||
class DividerInterface:
|
||||
def __init__(self):
|
||||
self.x_op = Signal(3)
|
||||
self.x_src1 = Signal(32)
|
||||
self.x_src2 = Signal(32)
|
||||
self.x_valid = Signal()
|
||||
self.x_stall = Signal()
|
||||
|
||||
self.m_result = Signal(32)
|
||||
self.m_busy = Signal()
|
||||
|
||||
|
||||
class Divider(DividerInterface, Elaboratable):
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
x_enable = Signal()
|
||||
x_modulus = Signal()
|
||||
x_signed = Signal()
|
||||
|
||||
with m.Switch(self.x_op):
|
||||
with m.Case(Funct3.DIV):
|
||||
m.d.comb += x_enable.eq(1), x_signed.eq(1)
|
||||
with m.Case(Funct3.DIVU):
|
||||
m.d.comb += x_enable.eq(1)
|
||||
with m.Case(Funct3.REM):
|
||||
m.d.comb += x_enable.eq(1), x_modulus.eq(1), x_signed.eq(1)
|
||||
with m.Case(Funct3.REMU):
|
||||
m.d.comb += x_enable.eq(1), x_modulus.eq(1)
|
||||
|
||||
x_negative = Signal()
|
||||
with m.If(x_modulus):
|
||||
m.d.comb += x_negative.eq(x_signed & self.x_src1[31])
|
||||
with m.Else():
|
||||
m.d.comb += x_negative.eq(x_signed & (self.x_src1[31] ^ self.x_src2[31]))
|
||||
|
||||
x_dividend = Signal(32)
|
||||
x_divisor = Signal(32)
|
||||
m.d.comb += [
|
||||
x_dividend.eq(Mux(x_signed & self.x_src1[31], -self.x_src1, self.x_src1)),
|
||||
x_divisor.eq(Mux(x_signed & self.x_src2[31], -self.x_src2, self.x_src2))
|
||||
]
|
||||
|
||||
m_modulus = Signal()
|
||||
m_negative = Signal()
|
||||
|
||||
timer = Signal(range(33), reset=32)
|
||||
quotient = Signal(32)
|
||||
divisor = Signal(32)
|
||||
remainder = Signal(32)
|
||||
difference = Signal(33)
|
||||
|
||||
with m.FSM() as fsm:
|
||||
with m.State("IDLE"):
|
||||
with m.If(x_enable & self.x_valid & ~self.x_stall):
|
||||
m.d.sync += [
|
||||
m_modulus.eq(x_modulus),
|
||||
m_negative.eq(x_negative)
|
||||
]
|
||||
with m.If(x_divisor == 0):
|
||||
# Division by zero
|
||||
m.d.sync += [
|
||||
quotient.eq(-1),
|
||||
remainder.eq(self.x_src1)
|
||||
]
|
||||
with m.Elif(x_signed & (self.x_src1 == -2**31) & (self.x_src2 == -1)):
|
||||
# Signed overflow
|
||||
m.d.sync += [
|
||||
quotient.eq(self.x_src1),
|
||||
remainder.eq(0)
|
||||
]
|
||||
with m.Elif(x_dividend == 0):
|
||||
m.d.sync += [
|
||||
quotient.eq(0),
|
||||
remainder.eq(0)
|
||||
]
|
||||
with m.Else():
|
||||
m.d.sync += [
|
||||
quotient.eq(x_dividend),
|
||||
remainder.eq(0),
|
||||
divisor.eq(x_divisor),
|
||||
timer.eq(timer.reset)
|
||||
]
|
||||
m.next = "DIVIDE"
|
||||
|
||||
with m.State("DIVIDE"):
|
||||
m.d.comb += self.m_busy.eq(1)
|
||||
with m.If(timer != 0):
|
||||
m.d.sync += timer.eq(timer - 1)
|
||||
m.d.comb += difference.eq(Cat(quotient[31], remainder) - divisor)
|
||||
with m.If(difference[32]):
|
||||
m.d.sync += [
|
||||
remainder.eq(Cat(quotient[31], remainder)),
|
||||
quotient.eq(Cat(0, quotient))
|
||||
]
|
||||
with m.Else():
|
||||
m.d.sync += [
|
||||
remainder.eq(difference),
|
||||
quotient.eq(Cat(1, quotient))
|
||||
]
|
||||
with m.Else():
|
||||
m.d.sync += [
|
||||
quotient.eq(Mux(m_negative, -quotient, quotient)),
|
||||
remainder.eq(Mux(m_negative, -remainder, remainder))
|
||||
]
|
||||
m.next = "IDLE"
|
||||
|
||||
m.d.comb += self.m_result.eq(Mux(m_modulus, remainder, quotient))
|
||||
|
||||
return m
|
||||
|
||||
|
||||
class DummyDivider(DividerInterface, Elaboratable):
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
x_result = Signal.like(self.m_result)
|
||||
|
||||
with m.Switch(self.x_op):
|
||||
# As per the RVFI specification (§ "Alternative Arithmetic Operations").
|
||||
# https://github.com/SymbioticEDA/riscv-formal/blob/master/docs/rvfi.md
|
||||
with m.Case(Funct3.DIV):
|
||||
m.d.comb += x_result.eq((self.x_src1 - self.x_src2) ^ C(0x7f8529ec))
|
||||
with m.Case(Funct3.DIVU):
|
||||
m.d.comb += x_result.eq((self.x_src1 - self.x_src2) ^ C(0x10e8fd70))
|
||||
with m.Case(Funct3.REM):
|
||||
m.d.comb += x_result.eq((self.x_src1 - self.x_src2) ^ C(0x8da68fa5))
|
||||
with m.Case(Funct3.REMU):
|
||||
m.d.comb += x_result.eq((self.x_src1 - self.x_src2) ^ C(0x3138d0e1))
|
||||
|
||||
with m.If(~self.x_stall):
|
||||
m.d.sync += self.m_result.eq(x_result)
|
||||
|
||||
m.d.comb += self.m_busy.eq(C(0))
|
||||
|
||||
return m
|
||||
121
cores/minerva/minerva/units/exception.py
Normal file
121
cores/minerva/minerva/units/exception.py
Normal file
@ -0,0 +1,121 @@
|
||||
from nmigen import *
|
||||
from nmigen.lib.coding import PriorityEncoder
|
||||
|
||||
from ..csr import *
|
||||
from ..isa import *
|
||||
|
||||
|
||||
__all__ = ["ExceptionUnit"]
|
||||
|
||||
|
||||
class ExceptionUnit(Elaboratable, AutoCSR):
|
||||
def __init__(self):
|
||||
self.mstatus = CSR(0x300, mstatus_layout)
|
||||
self.misa = CSR(0x301, misa_layout) # FIXME move elsewhere
|
||||
self.mie = CSR(0x304, mie_layout)
|
||||
self.mtvec = CSR(0x305, mtvec_layout)
|
||||
self.mscratch = CSR(0x340, flat_layout) # FIXME move elsewhere
|
||||
self.mepc = CSR(0x341, mepc_layout)
|
||||
self.mcause = CSR(0x342, mcause_layout)
|
||||
self.mtval = CSR(0x343, flat_layout)
|
||||
self.mip = CSR(0x344, mip_layout)
|
||||
self.irq_mask = CSR(0x330, flat_layout)
|
||||
self.irq_pending = CSR(0x360, flat_layout)
|
||||
|
||||
self.external_interrupt = Signal(32)
|
||||
self.timer_interrupt = Signal()
|
||||
self.software_interrupt = Signal()
|
||||
|
||||
self.m_fetch_misaligned = Signal()
|
||||
self.m_fetch_error = Signal()
|
||||
self.m_fetch_badaddr = Signal(30)
|
||||
self.m_load_misaligned = Signal()
|
||||
self.m_load_error = Signal()
|
||||
self.m_store_misaligned = Signal()
|
||||
self.m_store_error = Signal()
|
||||
self.m_loadstore_badaddr = Signal(30)
|
||||
self.m_branch_target = Signal(32)
|
||||
self.m_illegal = Signal()
|
||||
self.m_ebreak = Signal()
|
||||
self.m_ecall = Signal()
|
||||
self.m_pc = Signal(32)
|
||||
self.m_instruction = Signal(32)
|
||||
self.m_result = Signal(32)
|
||||
self.m_mret = Signal()
|
||||
self.m_stall = Signal()
|
||||
self.m_valid = Signal()
|
||||
|
||||
self.m_raise = Signal()
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
for csr in self.iter_csrs():
|
||||
with m.If(csr.we):
|
||||
m.d.sync += csr.r.eq(csr.w)
|
||||
|
||||
trap_pe = m.submodules.trap_pe = PriorityEncoder(16)
|
||||
m.d.comb += [
|
||||
trap_pe.i[Cause.FETCH_MISALIGNED ].eq(self.m_fetch_misaligned),
|
||||
trap_pe.i[Cause.FETCH_ACCESS_FAULT ].eq(self.m_fetch_error),
|
||||
trap_pe.i[Cause.ILLEGAL_INSTRUCTION].eq(self.m_illegal),
|
||||
trap_pe.i[Cause.BREAKPOINT ].eq(self.m_ebreak),
|
||||
trap_pe.i[Cause.LOAD_MISALIGNED ].eq(self.m_load_misaligned),
|
||||
trap_pe.i[Cause.LOAD_ACCESS_FAULT ].eq(self.m_load_error),
|
||||
trap_pe.i[Cause.STORE_MISALIGNED ].eq(self.m_store_misaligned),
|
||||
trap_pe.i[Cause.STORE_ACCESS_FAULT ].eq(self.m_store_error),
|
||||
trap_pe.i[Cause.ECALL_FROM_M ].eq(self.m_ecall)
|
||||
]
|
||||
|
||||
m.d.sync += [
|
||||
self.irq_pending.r.eq(self.external_interrupt & self.irq_mask.r),
|
||||
self.mip.r.msip.eq(self.software_interrupt),
|
||||
self.mip.r.mtip.eq(self.timer_interrupt),
|
||||
self.mip.r.meip.eq(self.irq_pending.r.bool())
|
||||
]
|
||||
|
||||
interrupt_pe = m.submodules.interrupt_pe = PriorityEncoder(16)
|
||||
m.d.comb += [
|
||||
interrupt_pe.i[Cause.M_SOFTWARE_INTERRUPT].eq(self.mip.r.msip & self.mie.r.msie),
|
||||
interrupt_pe.i[Cause.M_TIMER_INTERRUPT ].eq(self.mip.r.mtip & self.mie.r.mtie),
|
||||
interrupt_pe.i[Cause.M_EXTERNAL_INTERRUPT].eq(self.mip.r.meip & self.mie.r.meie)
|
||||
]
|
||||
|
||||
m.d.comb += self.m_raise.eq(~trap_pe.n | ~interrupt_pe.n & self.mstatus.r.mie)
|
||||
|
||||
with m.If(self.m_valid & ~self.m_stall):
|
||||
with m.If(self.m_raise):
|
||||
m.d.sync += [
|
||||
self.mstatus.r.mpie.eq(self.mstatus.r.mie),
|
||||
self.mstatus.r.mie.eq(0),
|
||||
self.mepc.r.base.eq(self.m_pc[2:])
|
||||
]
|
||||
with m.If(~trap_pe.n):
|
||||
m.d.sync += [
|
||||
self.mcause.r.ecode.eq(trap_pe.o),
|
||||
self.mcause.r.interrupt.eq(0)
|
||||
]
|
||||
with m.Switch(trap_pe.o):
|
||||
with m.Case(Cause.FETCH_MISALIGNED):
|
||||
m.d.sync += self.mtval.r.eq(self.m_branch_target)
|
||||
with m.Case(Cause.FETCH_ACCESS_FAULT):
|
||||
m.d.sync += self.mtval.r.eq(self.m_fetch_badaddr << 2)
|
||||
with m.Case(Cause.ILLEGAL_INSTRUCTION):
|
||||
m.d.sync += self.mtval.r.eq(self.m_instruction)
|
||||
with m.Case(Cause.BREAKPOINT):
|
||||
m.d.sync += self.mtval.r.eq(self.m_pc)
|
||||
with m.Case(Cause.LOAD_MISALIGNED, Cause.STORE_MISALIGNED):
|
||||
m.d.sync += self.mtval.r.eq(self.m_result)
|
||||
with m.Case(Cause.LOAD_ACCESS_FAULT, Cause.STORE_ACCESS_FAULT):
|
||||
m.d.sync += self.mtval.r.eq(self.m_loadstore_badaddr << 2)
|
||||
with m.Case():
|
||||
m.d.sync += self.mtval.r.eq(0)
|
||||
with m.Else():
|
||||
m.d.sync += [
|
||||
self.mcause.r.ecode.eq(interrupt_pe.o),
|
||||
self.mcause.r.interrupt.eq(1)
|
||||
]
|
||||
with m.Elif(self.m_mret):
|
||||
m.d.sync += self.mstatus.r.mie.eq(self.mstatus.r.mpie)
|
||||
|
||||
return m
|
||||
231
cores/minerva/minerva/units/fetch.py
Normal file
231
cores/minerva/minerva/units/fetch.py
Normal file
@ -0,0 +1,231 @@
|
||||
from nmigen import *
|
||||
from nmigen.utils import log2_int
|
||||
|
||||
from ..cache import *
|
||||
from ..wishbone import *
|
||||
|
||||
|
||||
__all__ = ["PCSelector", "FetchUnitInterface", "BareFetchUnit", "CachedFetchUnit"]
|
||||
|
||||
|
||||
class PCSelector(Elaboratable):
|
||||
def __init__(self):
|
||||
self.f_pc = Signal(32)
|
||||
self.d_pc = Signal(32)
|
||||
self.d_branch_predict_taken = Signal()
|
||||
self.d_branch_target = Signal(32)
|
||||
self.d_valid = Signal()
|
||||
self.x_pc = Signal(32)
|
||||
self.x_fence_i = Signal()
|
||||
self.x_valid = Signal()
|
||||
self.m_branch_predict_taken = Signal()
|
||||
self.m_branch_taken = Signal()
|
||||
self.m_branch_target = Signal(32)
|
||||
self.m_exception = Signal()
|
||||
self.m_mret = Signal()
|
||||
self.m_valid = Signal()
|
||||
self.mtvec_r_base = Signal(30)
|
||||
self.mepc_r_base = Signal(30)
|
||||
|
||||
self.a_pc = Signal(32)
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
m_sel = Signal(reset=1)
|
||||
m_a_pc = Signal(32)
|
||||
|
||||
with m.If(self.m_exception):
|
||||
m.d.comb += m_a_pc[2:].eq(self.mtvec_r_base)
|
||||
with m.Elif(self.m_mret):
|
||||
m.d.comb += m_a_pc[2:].eq(self.mepc_r_base)
|
||||
with m.Elif(self.m_branch_predict_taken & ~self.m_branch_taken):
|
||||
m.d.comb += m_a_pc[2:].eq(self.x_pc[2:])
|
||||
with m.Elif(~self.m_branch_predict_taken & self.m_branch_taken):
|
||||
m.d.comb += m_a_pc[2:].eq(self.m_branch_target[2:]),
|
||||
with m.Else():
|
||||
m.d.comb += m_sel.eq(0)
|
||||
|
||||
with m.If(m_sel & self.m_valid):
|
||||
m.d.comb += self.a_pc[2:].eq(m_a_pc[2:])
|
||||
with m.Elif(self.x_fence_i & self.x_valid):
|
||||
m.d.comb += self.a_pc[2:].eq(self.d_pc[2:])
|
||||
with m.Elif(self.d_branch_predict_taken & self.d_valid):
|
||||
m.d.comb += self.a_pc[2:].eq(self.d_branch_target[2:]),
|
||||
with m.Else():
|
||||
m.d.comb += self.a_pc[2:].eq(self.f_pc[2:] + 1)
|
||||
|
||||
return m
|
||||
|
||||
|
||||
class FetchUnitInterface:
|
||||
def __init__(self):
|
||||
self.ibus = Record(wishbone_layout)
|
||||
|
||||
self.a_pc = Signal(32)
|
||||
self.a_stall = Signal()
|
||||
self.a_valid = Signal()
|
||||
self.f_stall = Signal()
|
||||
self.f_valid = Signal()
|
||||
|
||||
self.a_busy = Signal()
|
||||
self.f_busy = Signal()
|
||||
self.f_instruction = Signal(32, reset=0x00000013) # nop (addi x0, x0, 0)
|
||||
self.f_fetch_error = Signal()
|
||||
self.f_badaddr = Signal(30)
|
||||
|
||||
|
||||
class BareFetchUnit(FetchUnitInterface, Elaboratable):
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
ibus_rdata = Signal.like(self.ibus.dat_r)
|
||||
with m.If(self.ibus.cyc):
|
||||
with m.If(self.ibus.ack | self.ibus.err | ~self.f_valid):
|
||||
m.d.sync += [
|
||||
self.ibus.cyc.eq(0),
|
||||
self.ibus.stb.eq(0),
|
||||
ibus_rdata.eq(self.ibus.dat_r)
|
||||
]
|
||||
with m.Elif(self.a_valid & ~self.a_stall):
|
||||
m.d.sync += [
|
||||
self.ibus.adr.eq(self.a_pc[2:]),
|
||||
self.ibus.cyc.eq(1),
|
||||
self.ibus.stb.eq(1)
|
||||
]
|
||||
m.d.comb += self.ibus.sel.eq(0b1111)
|
||||
|
||||
with m.If(self.ibus.cyc & self.ibus.err):
|
||||
m.d.sync += [
|
||||
self.f_fetch_error.eq(1),
|
||||
self.f_badaddr.eq(self.ibus.adr)
|
||||
]
|
||||
with m.Elif(~self.f_stall):
|
||||
m.d.sync += self.f_fetch_error.eq(0)
|
||||
|
||||
m.d.comb += self.a_busy.eq(self.ibus.cyc)
|
||||
|
||||
with m.If(self.f_fetch_error):
|
||||
m.d.comb += self.f_busy.eq(0)
|
||||
with m.Else():
|
||||
m.d.comb += [
|
||||
self.f_busy.eq(self.ibus.cyc),
|
||||
self.f_instruction.eq(ibus_rdata)
|
||||
]
|
||||
|
||||
return m
|
||||
|
||||
|
||||
class CachedFetchUnit(FetchUnitInterface, Elaboratable):
|
||||
def __init__(self, *icache_args):
|
||||
super().__init__()
|
||||
|
||||
self.icache_args = icache_args
|
||||
|
||||
self.f_pc = Signal(32)
|
||||
self.a_flush = Signal()
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
icache = m.submodules.icache = L1Cache(*self.icache_args)
|
||||
|
||||
a_icache_select = Signal()
|
||||
|
||||
# Test whether the target address is inside the L1 cache region. We use bit masks in order
|
||||
# to avoid carry chains from arithmetic comparisons. This restricts the region boundaries
|
||||
# to powers of 2.
|
||||
with m.Switch(self.a_pc[2:]):
|
||||
def addr_below(limit):
|
||||
assert limit in range(1, 2**30 + 1)
|
||||
range_bits = log2_int(limit)
|
||||
const_bits = 30 - range_bits
|
||||
return "{}{}".format("0" * const_bits, "-" * range_bits)
|
||||
|
||||
if icache.base >= 4:
|
||||
with m.Case(addr_below(icache.base >> 2)):
|
||||
m.d.comb += a_icache_select.eq(0)
|
||||
with m.Case(addr_below(icache.limit >> 2)):
|
||||
m.d.comb += a_icache_select.eq(1)
|
||||
with m.Default():
|
||||
m.d.comb += a_icache_select.eq(0)
|
||||
|
||||
f_icache_select = Signal()
|
||||
f_flush = Signal()
|
||||
|
||||
with m.If(~self.a_stall):
|
||||
m.d.sync += [
|
||||
f_icache_select.eq(a_icache_select),
|
||||
f_flush.eq(self.a_flush),
|
||||
]
|
||||
|
||||
m.d.comb += [
|
||||
icache.s1_addr.eq(self.a_pc[2:]),
|
||||
icache.s1_stall.eq(self.a_stall),
|
||||
icache.s1_valid.eq(self.a_valid),
|
||||
icache.s2_addr.eq(self.f_pc[2:]),
|
||||
icache.s2_re.eq(f_icache_select),
|
||||
icache.s2_evict.eq(Const(0)),
|
||||
icache.s2_flush.eq(f_flush),
|
||||
icache.s2_valid.eq(self.f_valid),
|
||||
]
|
||||
|
||||
ibus_arbiter = m.submodules.ibus_arbiter = WishboneArbiter()
|
||||
m.d.comb += ibus_arbiter.bus.connect(self.ibus)
|
||||
|
||||
icache_port = ibus_arbiter.port(priority=0)
|
||||
m.d.comb += [
|
||||
icache_port.cyc.eq(icache.bus_re),
|
||||
icache_port.stb.eq(icache.bus_re),
|
||||
icache_port.adr.eq(icache.bus_addr),
|
||||
icache_port.sel.eq(0b1111),
|
||||
icache_port.cti.eq(Mux(icache.bus_last, Cycle.END, Cycle.INCREMENT)),
|
||||
icache_port.bte.eq(Const(log2_int(icache.nwords) - 1)),
|
||||
icache.bus_valid.eq(icache_port.ack),
|
||||
icache.bus_error.eq(icache_port.err),
|
||||
icache.bus_rdata.eq(icache_port.dat_r)
|
||||
]
|
||||
|
||||
bare_port = ibus_arbiter.port(priority=1)
|
||||
bare_rdata = Signal.like(bare_port.dat_r)
|
||||
with m.If(bare_port.cyc):
|
||||
with m.If(bare_port.ack | bare_port.err | ~self.f_valid):
|
||||
m.d.sync += [
|
||||
bare_port.cyc.eq(0),
|
||||
bare_port.stb.eq(0),
|
||||
bare_rdata.eq(bare_port.dat_r)
|
||||
]
|
||||
with m.Elif(~a_icache_select & self.a_valid & ~self.a_stall):
|
||||
m.d.sync += [
|
||||
bare_port.cyc.eq(1),
|
||||
bare_port.stb.eq(1),
|
||||
bare_port.adr.eq(self.a_pc[2:])
|
||||
]
|
||||
m.d.comb += bare_port.sel.eq(0b1111)
|
||||
|
||||
m.d.comb += self.a_busy.eq(bare_port.cyc)
|
||||
|
||||
with m.If(self.ibus.cyc & self.ibus.err):
|
||||
m.d.sync += [
|
||||
self.f_fetch_error.eq(1),
|
||||
self.f_badaddr.eq(self.ibus.adr)
|
||||
]
|
||||
with m.Elif(~self.f_stall):
|
||||
m.d.sync += self.f_fetch_error.eq(0)
|
||||
|
||||
with m.If(f_flush):
|
||||
m.d.comb += self.f_busy.eq(~icache.s2_flush_ack)
|
||||
with m.Elif(self.f_fetch_error):
|
||||
m.d.comb += self.f_busy.eq(0)
|
||||
with m.Elif(f_icache_select):
|
||||
m.d.comb += [
|
||||
self.f_busy.eq(icache.s2_miss),
|
||||
self.f_instruction.eq(icache.s2_rdata)
|
||||
]
|
||||
with m.Else():
|
||||
m.d.comb += [
|
||||
self.f_busy.eq(bare_port.cyc),
|
||||
self.f_instruction.eq(bare_rdata)
|
||||
]
|
||||
|
||||
return m
|
||||
294
cores/minerva/minerva/units/loadstore.py
Normal file
294
cores/minerva/minerva/units/loadstore.py
Normal file
@ -0,0 +1,294 @@
|
||||
from nmigen import *
|
||||
from nmigen.utils import log2_int
|
||||
from nmigen.lib.fifo import SyncFIFO
|
||||
|
||||
from ..cache import *
|
||||
from ..isa import Funct3
|
||||
from ..wishbone import *
|
||||
|
||||
|
||||
__all__ = ["DataSelector", "LoadStoreUnitInterface", "BareLoadStoreUnit", "CachedLoadStoreUnit"]
|
||||
|
||||
|
||||
class DataSelector(Elaboratable):
|
||||
def __init__(self):
|
||||
self.x_offset = Signal(2)
|
||||
self.x_funct3 = Signal(3)
|
||||
self.x_store_operand = Signal(32)
|
||||
self.w_offset = Signal(2)
|
||||
self.w_funct3 = Signal(3)
|
||||
self.w_load_data = Signal(32)
|
||||
|
||||
self.x_misaligned = Signal()
|
||||
self.x_mask = Signal(4)
|
||||
self.x_store_data = Signal(32)
|
||||
self.w_load_result = Signal((32, True))
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
with m.Switch(self.x_funct3):
|
||||
with m.Case(Funct3.H, Funct3.HU):
|
||||
m.d.comb += self.x_misaligned.eq(self.x_offset[0])
|
||||
with m.Case(Funct3.W):
|
||||
m.d.comb += self.x_misaligned.eq(self.x_offset.bool())
|
||||
|
||||
with m.Switch(self.x_funct3):
|
||||
with m.Case(Funct3.B, Funct3.BU):
|
||||
m.d.comb += self.x_mask.eq(0b1 << self.x_offset)
|
||||
with m.Case(Funct3.H, Funct3.HU):
|
||||
m.d.comb += self.x_mask.eq(0b11 << self.x_offset)
|
||||
with m.Case(Funct3.W):
|
||||
m.d.comb += self.x_mask.eq(0b1111)
|
||||
|
||||
with m.Switch(self.x_funct3):
|
||||
with m.Case(Funct3.B):
|
||||
m.d.comb += self.x_store_data.eq(self.x_store_operand[:8] << self.x_offset*8)
|
||||
with m.Case(Funct3.H):
|
||||
m.d.comb += self.x_store_data.eq(self.x_store_operand[:16] << self.x_offset[1]*16)
|
||||
with m.Case(Funct3.W):
|
||||
m.d.comb += self.x_store_data.eq(self.x_store_operand)
|
||||
|
||||
w_byte = Signal((8, True))
|
||||
w_half = Signal((16, True))
|
||||
|
||||
m.d.comb += [
|
||||
w_byte.eq(self.w_load_data.word_select(self.w_offset, 8)),
|
||||
w_half.eq(self.w_load_data.word_select(self.w_offset[1], 16))
|
||||
]
|
||||
|
||||
with m.Switch(self.w_funct3):
|
||||
with m.Case(Funct3.B):
|
||||
m.d.comb += self.w_load_result.eq(w_byte)
|
||||
with m.Case(Funct3.BU):
|
||||
m.d.comb += self.w_load_result.eq(Cat(w_byte, 0))
|
||||
with m.Case(Funct3.H):
|
||||
m.d.comb += self.w_load_result.eq(w_half)
|
||||
with m.Case(Funct3.HU):
|
||||
m.d.comb += self.w_load_result.eq(Cat(w_half, 0))
|
||||
with m.Case(Funct3.W):
|
||||
m.d.comb += self.w_load_result.eq(self.w_load_data)
|
||||
|
||||
return m
|
||||
|
||||
|
||||
class LoadStoreUnitInterface:
|
||||
def __init__(self):
|
||||
self.dbus = Record(wishbone_layout)
|
||||
|
||||
self.x_addr = Signal(32)
|
||||
self.x_mask = Signal(4)
|
||||
self.x_load = Signal()
|
||||
self.x_store = Signal()
|
||||
self.x_store_data = Signal(32)
|
||||
self.x_stall = Signal()
|
||||
self.x_valid = Signal()
|
||||
self.m_stall = Signal()
|
||||
self.m_valid = Signal()
|
||||
|
||||
self.x_busy = Signal()
|
||||
self.m_busy = Signal()
|
||||
self.m_load_data = Signal(32)
|
||||
self.m_load_error = Signal()
|
||||
self.m_store_error = Signal()
|
||||
self.m_badaddr = Signal(30)
|
||||
|
||||
|
||||
class BareLoadStoreUnit(LoadStoreUnitInterface, Elaboratable):
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
with m.If(self.dbus.cyc):
|
||||
with m.If(self.dbus.ack | self.dbus.err | ~self.m_valid):
|
||||
m.d.sync += [
|
||||
self.dbus.cyc.eq(0),
|
||||
self.dbus.stb.eq(0),
|
||||
self.m_load_data.eq(self.dbus.dat_r)
|
||||
]
|
||||
with m.Elif((self.x_load | self.x_store) & self.x_valid & ~self.x_stall):
|
||||
m.d.sync += [
|
||||
self.dbus.cyc.eq(1),
|
||||
self.dbus.stb.eq(1),
|
||||
self.dbus.adr.eq(self.x_addr[2:]),
|
||||
self.dbus.sel.eq(self.x_mask),
|
||||
self.dbus.we.eq(self.x_store),
|
||||
self.dbus.dat_w.eq(self.x_store_data)
|
||||
]
|
||||
|
||||
with m.If(self.dbus.cyc & self.dbus.err):
|
||||
m.d.sync += [
|
||||
self.m_load_error.eq(~self.dbus.we),
|
||||
self.m_store_error.eq(self.dbus.we),
|
||||
self.m_badaddr.eq(self.dbus.adr)
|
||||
]
|
||||
with m.Elif(~self.m_stall):
|
||||
m.d.sync += [
|
||||
self.m_load_error.eq(0),
|
||||
self.m_store_error.eq(0)
|
||||
]
|
||||
|
||||
m.d.comb += self.x_busy.eq(self.dbus.cyc)
|
||||
|
||||
with m.If(self.m_load_error | self.m_store_error):
|
||||
m.d.comb += self.m_busy.eq(0)
|
||||
with m.Else():
|
||||
m.d.comb += self.m_busy.eq(self.dbus.cyc)
|
||||
|
||||
return m
|
||||
|
||||
|
||||
class CachedLoadStoreUnit(LoadStoreUnitInterface, Elaboratable):
|
||||
def __init__(self, *dcache_args):
|
||||
super().__init__()
|
||||
|
||||
self.dcache_args = dcache_args
|
||||
|
||||
self.x_fence_i = Signal()
|
||||
self.m_load = Signal()
|
||||
self.m_store = Signal()
|
||||
self.m_flush = Signal()
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
dcache = m.submodules.dcache = L1Cache(*self.dcache_args)
|
||||
|
||||
x_dcache_select = Signal()
|
||||
|
||||
# Test whether the target address is inside the L1 cache region. We use bit masks in order
|
||||
# to avoid carry chains from arithmetic comparisons. This restricts the region boundaries
|
||||
# to powers of 2.
|
||||
with m.Switch(self.x_addr[2:]):
|
||||
def addr_below(limit):
|
||||
assert limit in range(1, 2**30 + 1)
|
||||
range_bits = log2_int(limit)
|
||||
const_bits = 30 - range_bits
|
||||
return "{}{}".format("0" * const_bits, "-" * range_bits)
|
||||
|
||||
if dcache.base >= 4:
|
||||
with m.Case(addr_below(dcache.base >> 2)):
|
||||
m.d.comb += x_dcache_select.eq(0)
|
||||
with m.Case(addr_below(dcache.limit >> 2)):
|
||||
m.d.comb += x_dcache_select.eq(1)
|
||||
with m.Default():
|
||||
m.d.comb += x_dcache_select.eq(0)
|
||||
|
||||
m_dcache_select = Signal()
|
||||
m_addr = Signal.like(self.x_addr)
|
||||
|
||||
with m.If(~self.x_stall):
|
||||
m.d.sync += [
|
||||
m_dcache_select.eq(x_dcache_select),
|
||||
m_addr.eq(self.x_addr),
|
||||
]
|
||||
|
||||
m.d.comb += [
|
||||
dcache.s1_addr.eq(self.x_addr[2:]),
|
||||
dcache.s1_stall.eq(self.x_stall),
|
||||
dcache.s1_valid.eq(self.x_valid),
|
||||
dcache.s2_addr.eq(m_addr[2:]),
|
||||
dcache.s2_re.eq(self.m_load & m_dcache_select),
|
||||
dcache.s2_evict.eq(self.m_store & m_dcache_select),
|
||||
dcache.s2_flush.eq(self.m_flush),
|
||||
dcache.s2_valid.eq(self.m_valid),
|
||||
]
|
||||
|
||||
wrbuf_w_data = Record([("addr", 30), ("mask", 4), ("data", 32)])
|
||||
wrbuf_r_data = Record.like(wrbuf_w_data)
|
||||
wrbuf = m.submodules.wrbuf = SyncFIFO(width=len(wrbuf_w_data), depth=dcache.nwords)
|
||||
m.d.comb += [
|
||||
wrbuf.w_data.eq(wrbuf_w_data),
|
||||
wrbuf_w_data.addr.eq(self.x_addr[2:]),
|
||||
wrbuf_w_data.mask.eq(self.x_mask),
|
||||
wrbuf_w_data.data.eq(self.x_store_data),
|
||||
wrbuf.w_en.eq(self.x_store & self.x_valid & x_dcache_select & ~self.x_stall),
|
||||
wrbuf_r_data.eq(wrbuf.r_data),
|
||||
]
|
||||
|
||||
dbus_arbiter = m.submodules.dbus_arbiter = WishboneArbiter()
|
||||
m.d.comb += dbus_arbiter.bus.connect(self.dbus)
|
||||
|
||||
wrbuf_port = dbus_arbiter.port(priority=0)
|
||||
m.d.comb += [
|
||||
wrbuf_port.cyc.eq(wrbuf.r_rdy),
|
||||
wrbuf_port.we.eq(Const(1)),
|
||||
]
|
||||
with m.If(wrbuf_port.stb):
|
||||
with m.If(wrbuf_port.ack | wrbuf_port.err):
|
||||
m.d.sync += wrbuf_port.stb.eq(0)
|
||||
m.d.comb += wrbuf.r_en.eq(1)
|
||||
with m.Elif(wrbuf.r_rdy):
|
||||
m.d.sync += [
|
||||
wrbuf_port.stb.eq(1),
|
||||
wrbuf_port.adr.eq(wrbuf_r_data.addr),
|
||||
wrbuf_port.sel.eq(wrbuf_r_data.mask),
|
||||
wrbuf_port.dat_w.eq(wrbuf_r_data.data)
|
||||
]
|
||||
|
||||
dcache_port = dbus_arbiter.port(priority=1)
|
||||
m.d.comb += [
|
||||
dcache_port.cyc.eq(dcache.bus_re),
|
||||
dcache_port.stb.eq(dcache.bus_re),
|
||||
dcache_port.adr.eq(dcache.bus_addr),
|
||||
dcache_port.sel.eq(0b1111),
|
||||
dcache_port.cti.eq(Mux(dcache.bus_last, Cycle.END, Cycle.INCREMENT)),
|
||||
dcache_port.bte.eq(Const(log2_int(dcache.nwords) - 1)),
|
||||
dcache.bus_valid.eq(dcache_port.ack),
|
||||
dcache.bus_error.eq(dcache_port.err),
|
||||
dcache.bus_rdata.eq(dcache_port.dat_r)
|
||||
]
|
||||
|
||||
bare_port = dbus_arbiter.port(priority=2)
|
||||
bare_rdata = Signal.like(bare_port.dat_r)
|
||||
with m.If(bare_port.cyc):
|
||||
with m.If(bare_port.ack | bare_port.err | ~self.m_valid):
|
||||
m.d.sync += [
|
||||
bare_port.cyc.eq(0),
|
||||
bare_port.stb.eq(0),
|
||||
bare_rdata.eq(bare_port.dat_r)
|
||||
]
|
||||
with m.Elif((self.x_load | self.x_store) & ~x_dcache_select & self.x_valid & ~self.x_stall):
|
||||
m.d.sync += [
|
||||
bare_port.cyc.eq(1),
|
||||
bare_port.stb.eq(1),
|
||||
bare_port.adr.eq(self.x_addr[2:]),
|
||||
bare_port.sel.eq(self.x_mask),
|
||||
bare_port.we.eq(self.x_store),
|
||||
bare_port.dat_w.eq(self.x_store_data)
|
||||
]
|
||||
|
||||
with m.If(self.dbus.cyc & self.dbus.err):
|
||||
m.d.sync += [
|
||||
self.m_load_error.eq(~self.dbus.we),
|
||||
self.m_store_error.eq(self.dbus.we),
|
||||
self.m_badaddr.eq(self.dbus.adr)
|
||||
]
|
||||
with m.Elif(~self.m_stall):
|
||||
m.d.sync += [
|
||||
self.m_load_error.eq(0),
|
||||
self.m_store_error.eq(0)
|
||||
]
|
||||
|
||||
with m.If(self.x_fence_i):
|
||||
m.d.comb += self.x_busy.eq(wrbuf.r_rdy)
|
||||
with m.Elif(x_dcache_select):
|
||||
m.d.comb += self.x_busy.eq(self.x_store & ~wrbuf.w_rdy)
|
||||
with m.Else():
|
||||
m.d.comb += self.x_busy.eq(bare_port.cyc)
|
||||
|
||||
with m.If(self.m_flush):
|
||||
m.d.comb += self.m_busy.eq(~dcache.s2_flush_ack)
|
||||
with m.If(self.m_load_error | self.m_store_error):
|
||||
m.d.comb += self.m_busy.eq(0)
|
||||
with m.Elif(m_dcache_select):
|
||||
m.d.comb += [
|
||||
self.m_busy.eq(self.m_load & dcache.s2_miss),
|
||||
self.m_load_data.eq(dcache.s2_rdata)
|
||||
]
|
||||
with m.Else():
|
||||
m.d.comb += [
|
||||
self.m_busy.eq(bare_port.cyc),
|
||||
self.m_load_data.eq(bare_rdata)
|
||||
]
|
||||
|
||||
return m
|
||||
28
cores/minerva/minerva/units/logic.py
Normal file
28
cores/minerva/minerva/units/logic.py
Normal file
@ -0,0 +1,28 @@
|
||||
from nmigen import *
|
||||
|
||||
from ..isa import Funct3
|
||||
|
||||
|
||||
__all__ = ["LogicUnit"]
|
||||
|
||||
|
||||
class LogicUnit(Elaboratable):
|
||||
def __init__(self):
|
||||
self.op = Signal(3)
|
||||
self.src1 = Signal(32)
|
||||
self.src2 = Signal(32)
|
||||
|
||||
self.result = Signal(32)
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
with m.Switch(self.op):
|
||||
with m.Case(Funct3.XOR):
|
||||
m.d.comb += self.result.eq(self.src1 ^ self.src2)
|
||||
with m.Case(Funct3.OR):
|
||||
m.d.comb += self.result.eq(self.src1 | self.src2)
|
||||
with m.Case(Funct3.AND):
|
||||
m.d.comb += self.result.eq(self.src1 & self.src2)
|
||||
|
||||
return m
|
||||
81
cores/minerva/minerva/units/multiplier.py
Normal file
81
cores/minerva/minerva/units/multiplier.py
Normal file
@ -0,0 +1,81 @@
|
||||
from nmigen import *
|
||||
|
||||
from ..isa import Funct3
|
||||
|
||||
|
||||
__all__ = ["MultiplierInterface", "Multiplier", "DummyMultiplier"]
|
||||
|
||||
|
||||
class MultiplierInterface:
|
||||
def __init__(self):
|
||||
self.x_op = Signal(3)
|
||||
self.x_src1 = Signal(32)
|
||||
self.x_src2 = Signal(32)
|
||||
self.x_stall = Signal()
|
||||
self.m_stall = Signal()
|
||||
|
||||
self.w_result = Signal(32)
|
||||
|
||||
|
||||
class Multiplier(MultiplierInterface, Elaboratable):
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
x_low = Signal()
|
||||
x_src1_signed = Signal()
|
||||
x_src2_signed = Signal()
|
||||
|
||||
m.d.comb += [
|
||||
x_low.eq(self.x_op == Funct3.MUL),
|
||||
x_src1_signed.eq((self.x_op == Funct3.MULH) | (self.x_op == Funct3.MULHSU)),
|
||||
x_src2_signed.eq(self.x_op == Funct3.MULH)
|
||||
]
|
||||
|
||||
x_src1 = Signal(signed(33))
|
||||
x_src2 = Signal(signed(33))
|
||||
|
||||
m.d.comb += [
|
||||
x_src1.eq(Cat(self.x_src1, x_src1_signed & self.x_src1[31])),
|
||||
x_src2.eq(Cat(self.x_src2, x_src2_signed & self.x_src2[31]))
|
||||
]
|
||||
|
||||
m_low = Signal()
|
||||
m_prod = Signal(signed(66))
|
||||
|
||||
with m.If(~self.x_stall):
|
||||
m.d.sync += [
|
||||
m_low.eq(x_low),
|
||||
m_prod.eq(x_src1 * x_src2)
|
||||
]
|
||||
|
||||
with m.If(~self.m_stall):
|
||||
m.d.sync += self.w_result.eq(Mux(m_low, m_prod[:32], m_prod[32:]))
|
||||
|
||||
return m
|
||||
|
||||
|
||||
class DummyMultiplier(MultiplierInterface, Elaboratable):
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
x_result = Signal.like(self.w_result)
|
||||
m_result = Signal.like(self.w_result)
|
||||
|
||||
with m.Switch(self.x_op):
|
||||
# As per the RVFI specification (§ "Alternative Arithmetic Operations").
|
||||
# https://github.com/SymbioticEDA/riscv-formal/blob/master/docs/rvfi.md
|
||||
with m.Case(Funct3.MUL):
|
||||
m.d.comb += x_result.eq((self.x_src1 + self.x_src2) ^ C(0x5876063e))
|
||||
with m.Case(Funct3.MULH):
|
||||
m.d.comb += x_result.eq((self.x_src1 + self.x_src2) ^ C(0xf6583fb7))
|
||||
with m.Case(Funct3.MULHSU):
|
||||
m.d.comb += x_result.eq((self.x_src1 - self.x_src2) ^ C(0xecfbe137))
|
||||
with m.Case(Funct3.MULHU):
|
||||
m.d.comb += x_result.eq((self.x_src1 + self.x_src2) ^ C(0x949ce5e8))
|
||||
|
||||
with m.If(~self.x_stall):
|
||||
m.d.sync += m_result.eq(x_result)
|
||||
with m.If(~self.m_stall):
|
||||
m.d.sync += self.w_result.eq(m_result)
|
||||
|
||||
return m
|
||||
38
cores/minerva/minerva/units/predict.py
Normal file
38
cores/minerva/minerva/units/predict.py
Normal file
@ -0,0 +1,38 @@
|
||||
from nmigen import *
|
||||
|
||||
|
||||
__all__ = ["BranchPredictor"]
|
||||
|
||||
|
||||
class BranchPredictor(Elaboratable):
|
||||
def __init__(self):
|
||||
self.d_branch = Signal()
|
||||
self.d_jump = Signal()
|
||||
self.d_offset = Signal((32, True))
|
||||
self.d_pc = Signal(32)
|
||||
self.d_rs1_re = Signal()
|
||||
|
||||
self.d_branch_taken = Signal()
|
||||
self.d_branch_target = Signal(32)
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
d_fetch_misaligned = Signal()
|
||||
m.d.comb += [
|
||||
d_fetch_misaligned.eq(self.d_pc[:2].bool() | self.d_offset[:2].bool()),
|
||||
self.d_branch_target.eq(self.d_pc + self.d_offset),
|
||||
]
|
||||
|
||||
with m.If(d_fetch_misaligned):
|
||||
m.d.comb += self.d_branch_taken.eq(0)
|
||||
with m.Elif(self.d_branch):
|
||||
# Backward conditional branches are predicted as taken.
|
||||
# Forward conditional branches are predicted as not taken.
|
||||
m.d.comb += self.d_branch_taken.eq(self.d_offset[-1])
|
||||
with m.Else():
|
||||
# Direct jumps are predicted as taken.
|
||||
# Other branch types (ie. indirect jumps, exceptions) are not predicted.
|
||||
m.d.comb += self.d_branch_taken.eq(self.d_jump & ~self.d_rs1_re)
|
||||
|
||||
return m
|
||||
197
cores/minerva/minerva/units/rvficon.py
Normal file
197
cores/minerva/minerva/units/rvficon.py
Normal file
@ -0,0 +1,197 @@
|
||||
from functools import reduce
|
||||
from operator import or_
|
||||
|
||||
from nmigen import *
|
||||
from nmigen.hdl.rec import *
|
||||
|
||||
from ..isa import *
|
||||
from ..wishbone import *
|
||||
|
||||
|
||||
__all__ = ["rvfi_layout", "RVFIController"]
|
||||
|
||||
# RISC-V Formal Interface
|
||||
# https://github.com/SymbioticEDA/riscv-formal/blob/master/docs/rvfi.md
|
||||
|
||||
rvfi_layout = [
|
||||
("valid", 1, DIR_FANOUT),
|
||||
("order", 64, DIR_FANOUT),
|
||||
("insn", 32, DIR_FANOUT),
|
||||
("trap", 1, DIR_FANOUT),
|
||||
("halt", 1, DIR_FANOUT),
|
||||
("intr", 1, DIR_FANOUT),
|
||||
("mode", 2, DIR_FANOUT),
|
||||
("ixl", 2, DIR_FANOUT),
|
||||
|
||||
("rs1_addr", 5, DIR_FANOUT),
|
||||
("rs2_addr", 5, DIR_FANOUT),
|
||||
("rs1_rdata", 32, DIR_FANOUT),
|
||||
("rs2_rdata", 32, DIR_FANOUT),
|
||||
("rd_addr", 5, DIR_FANOUT),
|
||||
("rd_wdata", 32, DIR_FANOUT),
|
||||
|
||||
("pc_rdata", 32, DIR_FANOUT),
|
||||
("pc_wdata", 32, DIR_FANOUT),
|
||||
|
||||
("mem_addr", 32, DIR_FANOUT),
|
||||
("mem_rmask", 4, DIR_FANOUT),
|
||||
("mem_wmask", 4, DIR_FANOUT),
|
||||
("mem_rdata", 32, DIR_FANOUT),
|
||||
("mem_wdata", 32, DIR_FANOUT)
|
||||
]
|
||||
|
||||
|
||||
class RVFIController(Elaboratable):
|
||||
def __init__(self):
|
||||
self.rvfi = Record(rvfi_layout)
|
||||
|
||||
self.d_insn = Signal.like(self.rvfi.insn)
|
||||
self.d_rs1_addr = Signal.like(self.rvfi.rs1_addr)
|
||||
self.d_rs2_addr = Signal.like(self.rvfi.rs2_addr)
|
||||
self.d_rs1_rdata = Signal.like(self.rvfi.rs1_rdata)
|
||||
self.d_rs2_rdata = Signal.like(self.rvfi.rs2_rdata)
|
||||
self.d_stall = Signal()
|
||||
self.x_mem_addr = Signal.like(self.rvfi.mem_addr)
|
||||
self.x_mem_wmask = Signal.like(self.rvfi.mem_wmask)
|
||||
self.x_mem_rmask = Signal.like(self.rvfi.mem_rmask)
|
||||
self.x_mem_wdata = Signal.like(self.rvfi.mem_wdata)
|
||||
self.x_stall = Signal()
|
||||
self.m_mem_rdata = Signal.like(self.rvfi.mem_rdata)
|
||||
self.m_fetch_misaligned = Signal()
|
||||
self.m_illegal_insn = Signal()
|
||||
self.m_load_misaligned = Signal()
|
||||
self.m_store_misaligned = Signal()
|
||||
self.m_exception = Signal()
|
||||
self.m_mret = Signal()
|
||||
self.m_branch_taken = Signal()
|
||||
self.m_branch_target = Signal(32)
|
||||
self.m_pc_rdata = Signal.like(self.rvfi.pc_rdata)
|
||||
self.m_stall = Signal()
|
||||
self.m_valid = Signal()
|
||||
self.w_rd_addr = Signal.like(self.rvfi.rd_addr)
|
||||
self.w_rd_wdata = Signal.like(self.rvfi.rd_wdata)
|
||||
|
||||
self.mtvec_r_base = Signal(30)
|
||||
self.mepc_r_value = Signal(32)
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
# Instruction Metadata
|
||||
|
||||
with m.If(~self.m_stall):
|
||||
m.d.sync += self.rvfi.valid.eq(self.m_valid)
|
||||
with m.Elif(self.rvfi.valid):
|
||||
m.d.sync += self.rvfi.valid.eq(0)
|
||||
|
||||
with m.If(self.rvfi.valid):
|
||||
m.d.sync += self.rvfi.order.eq(self.rvfi.order + 1)
|
||||
|
||||
x_insn = Signal.like(self.rvfi.insn)
|
||||
m_insn = Signal.like(self.rvfi.insn)
|
||||
|
||||
with m.If(~self.d_stall):
|
||||
m.d.sync += x_insn.eq(self.d_insn)
|
||||
with m.If(~self.x_stall):
|
||||
m.d.sync += m_insn.eq(x_insn)
|
||||
with m.If(~self.m_stall):
|
||||
m.d.sync += self.rvfi.insn.eq(m_insn)
|
||||
|
||||
with m.If(~self.m_stall):
|
||||
m.d.sync += [
|
||||
self.rvfi.trap.eq(reduce(or_, (
|
||||
self.m_fetch_misaligned,
|
||||
self.m_illegal_insn,
|
||||
self.m_load_misaligned,
|
||||
self.m_store_misaligned
|
||||
))),
|
||||
self.rvfi.intr.eq(self.m_pc_rdata == self.mtvec_r_base << 2)
|
||||
]
|
||||
|
||||
m.d.comb += [
|
||||
self.rvfi.mode.eq(Const(3)), # M-mode
|
||||
self.rvfi.ixl.eq(Const(1)) # XLEN=32
|
||||
]
|
||||
|
||||
# Integer Register Read/Write
|
||||
|
||||
x_rs1_addr = Signal.like(self.rvfi.rs1_addr)
|
||||
x_rs2_addr = Signal.like(self.rvfi.rs2_addr)
|
||||
x_rs1_rdata = Signal.like(self.rvfi.rs1_rdata)
|
||||
x_rs2_rdata = Signal.like(self.rvfi.rs2_rdata)
|
||||
|
||||
m_rs1_addr = Signal.like(self.rvfi.rs1_addr)
|
||||
m_rs2_addr = Signal.like(self.rvfi.rs2_addr)
|
||||
m_rs1_rdata = Signal.like(self.rvfi.rs1_rdata)
|
||||
m_rs2_rdata = Signal.like(self.rvfi.rs2_rdata)
|
||||
|
||||
with m.If(~self.d_stall):
|
||||
m.d.sync += [
|
||||
x_rs1_addr.eq(self.d_rs1_addr),
|
||||
x_rs2_addr.eq(self.d_rs2_addr),
|
||||
x_rs1_rdata.eq(self.d_rs1_rdata),
|
||||
x_rs2_rdata.eq(self.d_rs2_rdata)
|
||||
]
|
||||
with m.If(~self.x_stall):
|
||||
m.d.sync += [
|
||||
m_rs1_addr.eq(x_rs1_addr),
|
||||
m_rs2_addr.eq(x_rs2_addr),
|
||||
m_rs1_rdata.eq(x_rs1_rdata),
|
||||
m_rs2_rdata.eq(x_rs2_rdata)
|
||||
]
|
||||
with m.If(~self.m_stall):
|
||||
m.d.sync += [
|
||||
self.rvfi.rs1_addr.eq(m_rs1_addr),
|
||||
self.rvfi.rs2_addr.eq(m_rs2_addr),
|
||||
self.rvfi.rs1_rdata.eq(m_rs1_rdata),
|
||||
self.rvfi.rs2_rdata.eq(m_rs2_rdata)
|
||||
]
|
||||
|
||||
m.d.comb += [
|
||||
self.rvfi.rd_addr.eq(self.w_rd_addr),
|
||||
self.rvfi.rd_wdata.eq(self.w_rd_wdata)
|
||||
]
|
||||
|
||||
# Program Counter
|
||||
|
||||
m_pc_wdata = Signal.like(self.rvfi.pc_wdata)
|
||||
|
||||
with m.If(self.m_exception):
|
||||
m.d.comb += m_pc_wdata.eq(self.mtvec_r_base << 2)
|
||||
with m.Elif(self.m_mret):
|
||||
m.d.comb += m_pc_wdata.eq(self.mepc_r_value)
|
||||
with m.Elif(self.m_branch_taken):
|
||||
m.d.comb += m_pc_wdata.eq(self.m_branch_target)
|
||||
with m.Else():
|
||||
m.d.comb += m_pc_wdata.eq(self.m_pc_rdata + 4)
|
||||
|
||||
with m.If(~self.m_stall):
|
||||
m.d.sync += [
|
||||
self.rvfi.pc_rdata.eq(self.m_pc_rdata),
|
||||
self.rvfi.pc_wdata.eq(m_pc_wdata)
|
||||
]
|
||||
|
||||
# Memory Access
|
||||
|
||||
m_mem_addr = Signal.like(self.rvfi.mem_addr)
|
||||
m_mem_wmask = Signal.like(self.rvfi.mem_wmask)
|
||||
m_mem_rmask = Signal.like(self.rvfi.mem_rmask)
|
||||
m_mem_wdata = Signal.like(self.rvfi.mem_wdata)
|
||||
|
||||
with m.If(~self.x_stall):
|
||||
m.d.sync += [
|
||||
m_mem_addr.eq(self.x_mem_addr),
|
||||
m_mem_wmask.eq(self.x_mem_wmask),
|
||||
m_mem_rmask.eq(self.x_mem_rmask),
|
||||
m_mem_wdata.eq(self.x_mem_wdata)
|
||||
]
|
||||
with m.If(~self.m_stall):
|
||||
m.d.sync += [
|
||||
self.rvfi.mem_addr.eq(m_mem_addr),
|
||||
self.rvfi.mem_wmask.eq(m_mem_wmask),
|
||||
self.rvfi.mem_rmask.eq(m_mem_rmask),
|
||||
self.rvfi.mem_wdata.eq(m_mem_wdata),
|
||||
self.rvfi.mem_rdata.eq(self.m_mem_rdata)
|
||||
]
|
||||
|
||||
return m
|
||||
39
cores/minerva/minerva/units/shifter.py
Normal file
39
cores/minerva/minerva/units/shifter.py
Normal file
@ -0,0 +1,39 @@
|
||||
from nmigen import *
|
||||
|
||||
|
||||
__all__ = ["Shifter"]
|
||||
|
||||
|
||||
class Shifter(Elaboratable):
|
||||
def __init__(self):
|
||||
self.x_direction = Signal()
|
||||
self.x_sext = Signal()
|
||||
self.x_shamt = Signal(5)
|
||||
self.x_src1 = Signal(32)
|
||||
self.x_stall = Signal()
|
||||
|
||||
self.m_result = Signal(32)
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
x_operand = Signal(32)
|
||||
x_filler = Signal()
|
||||
m_direction = Signal()
|
||||
m_result = Signal(32)
|
||||
|
||||
m.d.comb += [
|
||||
# left shifts are equivalent to right shifts with reversed bits
|
||||
x_operand.eq(Mux(self.x_direction, self.x_src1, self.x_src1[::-1])),
|
||||
x_filler.eq(Mux(self.x_direction & self.x_sext, self.x_src1[-1], 0))
|
||||
]
|
||||
|
||||
with m.If(~self.x_stall):
|
||||
m.d.sync += [
|
||||
m_direction.eq(self.x_direction),
|
||||
m_result.eq(Cat(x_operand, Repl(x_filler, 32)) >> self.x_shamt)
|
||||
]
|
||||
|
||||
m.d.comb += self.m_result.eq(Mux(m_direction, m_result, m_result[::-1]))
|
||||
|
||||
return m
|
||||
117
cores/minerva/minerva/units/trigger.py
Normal file
117
cores/minerva/minerva/units/trigger.py
Normal file
@ -0,0 +1,117 @@
|
||||
from functools import reduce
|
||||
from operator import or_
|
||||
|
||||
from nmigen import *
|
||||
from nmigen.hdl.rec import *
|
||||
|
||||
from ..csr import *
|
||||
from ..isa import *
|
||||
|
||||
|
||||
__all__ = ["TriggerUnit"]
|
||||
|
||||
|
||||
class Type:
|
||||
NOP = 0
|
||||
LEGACY = 1
|
||||
MATCH = 2
|
||||
INSN_COUNT = 3
|
||||
INTERRUPT = 4
|
||||
EXCEPTION = 5
|
||||
|
||||
|
||||
mcontrol_layout = [
|
||||
("load", 1),
|
||||
("store", 1),
|
||||
("execute", 1),
|
||||
("u", 1),
|
||||
("s", 1),
|
||||
("zero0", 1),
|
||||
("m", 1),
|
||||
("match", 4),
|
||||
("chain", 1),
|
||||
("action", 4),
|
||||
("size", 2),
|
||||
("timing", 1),
|
||||
("select", 1),
|
||||
("hit", 1),
|
||||
("maskmax", 6)
|
||||
]
|
||||
|
||||
|
||||
class TriggerUnit(Elaboratable, AutoCSR):
|
||||
def __init__(self, nb_triggers):
|
||||
if not isinstance(nb_triggers, int):
|
||||
raise TypeError("Number of triggers must be an int, not {!r}"
|
||||
.format(nb_triggers))
|
||||
if nb_triggers == 0 or nb_triggers & nb_triggers - 1:
|
||||
raise ValueError("Number of triggers must be a power of 2, not {!r}"
|
||||
.format(nb_triggers))
|
||||
self.nb_triggers = nb_triggers
|
||||
|
||||
self.tselect = CSR(0x7a0, flat_layout)
|
||||
self.tdata1 = CSR(0x7a1, tdata1_layout)
|
||||
self.tdata2 = CSR(0x7a2, flat_layout)
|
||||
|
||||
self.x_pc = Signal(32)
|
||||
self.x_valid = Signal()
|
||||
|
||||
self.haltreq = Signal()
|
||||
self.x_trap = Signal()
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
triggers = [Record.like(self.tdata1.r) for _ in range(self.nb_triggers)]
|
||||
for t in triggers:
|
||||
# We only support address/data match triggers.
|
||||
m.d.comb += t.type.eq(Type.MATCH)
|
||||
|
||||
def do_trigger_update(trigger):
|
||||
m.d.sync += trigger.dmode.eq(self.tdata1.w.dmode)
|
||||
mcontrol = Record([("i", mcontrol_layout), ("o", mcontrol_layout)])
|
||||
m.d.comb += [
|
||||
mcontrol.i.eq(self.tdata1.w.data),
|
||||
mcontrol.o.execute.eq(mcontrol.i.execute),
|
||||
mcontrol.o.m.eq(mcontrol.i.m),
|
||||
mcontrol.o.action.eq(mcontrol.i.action),
|
||||
]
|
||||
m.d.sync += trigger.data.eq(mcontrol.o)
|
||||
|
||||
with m.Switch(self.tselect.r.value):
|
||||
for i, t in enumerate(triggers):
|
||||
with m.Case(i):
|
||||
m.d.comb += self.tdata1.r.eq(t)
|
||||
with m.If(self.tdata1.we):
|
||||
do_trigger_update(t)
|
||||
|
||||
with m.If(self.tselect.we):
|
||||
with m.If(self.tselect.w.value & (self.nb_triggers - 1)):
|
||||
m.d.sync += self.tselect.r.value.eq(self.tselect.w.value)
|
||||
|
||||
with m.If(self.tdata2.we):
|
||||
m.d.sync += self.tdata2.r.eq(self.tdata2.w)
|
||||
|
||||
hit = Signal()
|
||||
halt = Signal()
|
||||
|
||||
with m.Switch(self.tdata1.r.type):
|
||||
with m.Case(Type.MATCH):
|
||||
mcontrol = Record(mcontrol_layout)
|
||||
m.d.comb += mcontrol.eq(self.tdata1.r.data)
|
||||
|
||||
match = Signal()
|
||||
with m.If(mcontrol.execute):
|
||||
m.d.comb += match.eq(self.tdata2.r == self.x_pc & self.x_valid)
|
||||
m.d.comb += [
|
||||
hit.eq(match & mcontrol.m),
|
||||
halt.eq(mcontrol.action)
|
||||
]
|
||||
|
||||
with m.If(hit):
|
||||
with m.If(halt):
|
||||
m.d.comb += self.haltreq.eq(self.tdata1.r.dmode)
|
||||
with m.Else():
|
||||
m.d.comb += self.x_trap.eq(1)
|
||||
|
||||
return m
|
||||
72
cores/minerva/minerva/wishbone.py
Normal file
72
cores/minerva/minerva/wishbone.py
Normal file
@ -0,0 +1,72 @@
|
||||
from nmigen import *
|
||||
from nmigen.hdl.rec import *
|
||||
from nmigen.lib.coding import *
|
||||
|
||||
|
||||
__all__ = ["Cycle", "wishbone_layout", "WishboneArbiter"]
|
||||
|
||||
|
||||
class Cycle:
|
||||
CLASSIC = 0
|
||||
CONSTANT = 1
|
||||
INCREMENT = 2
|
||||
END = 7
|
||||
|
||||
|
||||
wishbone_layout = [
|
||||
("adr", 30, DIR_FANOUT),
|
||||
("dat_w", 32, DIR_FANOUT),
|
||||
("dat_r", 32, DIR_FANIN),
|
||||
("sel", 4, DIR_FANOUT),
|
||||
("cyc", 1, DIR_FANOUT),
|
||||
("stb", 1, DIR_FANOUT),
|
||||
("ack", 1, DIR_FANIN),
|
||||
("we", 1, DIR_FANOUT),
|
||||
("cti", 3, DIR_FANOUT),
|
||||
("bte", 2, DIR_FANOUT),
|
||||
("err", 1, DIR_FANIN)
|
||||
]
|
||||
|
||||
|
||||
class WishboneArbiter(Elaboratable):
|
||||
def __init__(self):
|
||||
self.bus = Record(wishbone_layout)
|
||||
self._port_map = dict()
|
||||
|
||||
def port(self, priority):
|
||||
if not isinstance(priority, int) or priority < 0:
|
||||
raise TypeError("Priority must be a non-negative integer, not '{!r}'"
|
||||
.format(priority))
|
||||
if priority in self._port_map:
|
||||
raise ValueError("Conflicting priority: '{!r}'".format(priority))
|
||||
port = self._port_map[priority] = Record.like(self.bus)
|
||||
return port
|
||||
|
||||
def elaborate(self, platform):
|
||||
m = Module()
|
||||
|
||||
ports = [port for priority, port in sorted(self._port_map.items())]
|
||||
|
||||
for port in ports:
|
||||
m.d.comb += port.dat_r.eq(self.bus.dat_r)
|
||||
|
||||
bus_pe = m.submodules.bus_pe = PriorityEncoder(len(ports))
|
||||
with m.If(~self.bus.cyc):
|
||||
for j, port in enumerate(ports):
|
||||
m.d.sync += bus_pe.i[j].eq(port.cyc)
|
||||
|
||||
source = Array(ports)[bus_pe.o]
|
||||
m.d.comb += [
|
||||
self.bus.adr.eq(source.adr),
|
||||
self.bus.dat_w.eq(source.dat_w),
|
||||
self.bus.sel.eq(source.sel),
|
||||
self.bus.cyc.eq(source.cyc),
|
||||
self.bus.stb.eq(source.stb),
|
||||
self.bus.we.eq(source.we),
|
||||
self.bus.cti.eq(source.cti),
|
||||
self.bus.bte.eq(source.bte),
|
||||
source.ack.eq(self.bus.ack),
|
||||
source.err.eq(self.bus.err)
|
||||
]
|
||||
|
||||
return m
|
||||
19
cores/minerva/setup.py
Normal file
19
cores/minerva/setup.py
Normal file
@ -0,0 +1,19 @@
|
||||
from setuptools import setup, find_packages
|
||||
|
||||
|
||||
setup(
|
||||
name="minerva",
|
||||
version="0.1",
|
||||
description="A 32-bit RISC-V soft processor",
|
||||
author="Jean-François Nguyen",
|
||||
author_email="jf@lambdaconcept.com",
|
||||
license="BSD",
|
||||
python_requires="~=3.6",
|
||||
install_requires=["nmigen>=0.1rc1"],
|
||||
extras_require={ "debug": ["jtagtap"] },
|
||||
packages=find_packages(),
|
||||
project_urls={
|
||||
"Source Code": "https://github.com/lambdaconcept/minerva",
|
||||
"Bug Tracker": "https://github.com/lambdaconcept/minerva/issues"
|
||||
}
|
||||
)
|
||||
Loading…
Reference in New Issue
Block a user